短い答え
知識労働者は、MemoryLakeプロジェクトを作成し、そのコンテキスト(文書、ルール、好み)を読み込み、MCPサーバーエンドポイントを生成し、各AIツールをそのエンドポイントに接続することで、クロスツールAI記憶を設定できます。すべてのツールは同じプロジェクトを読み取ります — ツールを切り替えるときにコンテキストを再説明する必要はありません。
なぜ各AIツールの組み込み記憶が不十分なのか
ほとんどのAIツールは、何らかの形でセッション履歴や軽量の記憶機能を提供していますが、それぞれがサイロになっています。ChatGPT内で構築したコンテキストはClaudeには移動しません。コーディングエージェントで設定したルールはリサーチツールには表示されません。「あなたが誰で、何が必要か」の複数の不一致なコピーを維持することになり、必然的に同期が外れます。
また、共有所有権もありません。各ツールはあなたのコンテキストを独自の方法で要約または解釈するため、あなたが書いた正確な指示が言い換えられたり、削除されたりします。プロジェクトの途中でツールを切り替えると、そのコストをすぐに感じます:制約を説明するのに5分、用語を明確にするのにさらに2分、そしてAIが何かを誤解したときの避けられない修正。
リサーチ、ライティング、データ分析、コミュニケーションを3つまたは4つのAIツールで同時に行う知識労働者にとって、その摩擦はすぐに蓄積されます。本当のギャップは、どのツールの記憶でもなく、あなたのコンテキスト全体に対する単一の真実のソースが存在しないことです。
始める前に
必要なもの:
- 無料のMemoryLakeアカウント
- MCPをサポートする少なくとも1つのAIツール(Claude Desktop、Cursor、または他のMCP互換クライアント)
- 最も頻繁に繰り返すコンテキスト — プロジェクトブリーフ、スタイルルール、好み、または参照ファイル(PDF、Word、Excel、PowerPoint、Markdown、または画像)
知識労働者のためのクロスツール記憶の設定方法(ステップバイステップ)
ステップ1:記憶プロジェクトを構築する
MemoryLakeにサインインし、プロジェクト管理に移動します。プロジェクトを作成をクリックし、明確な名前を付けます — 例えば、「Work Context 2026」。プロジェクト内で、ドキュメントドライブを開き、アップロードをクリックしてプロジェクトブリーフ、スタイルガイド、リサーチノートなどの参照ファイルを追加します。次に、ドキュメントタブを開き、ドキュメントを追加をクリックし、アップロードしたファイルをプロジェクトに添付するために確認をクリックします。次に、記憶タブを開き、記憶を追加をクリックし、定常ルールまたは好み(例えば、好みの応答形式、繰り返しの制約、または重要な用語)を入力し、保存をクリックします。AIツールをオンボーディングするときに通常繰り返す各ルールについてこれを繰り返します。
ステップ2:MCPサーバーエンドポイントを生成する
プロジェクト内で、MCPサーバータブを開き、MCPサーバーを追加をクリックします。サーバーに説明的な名前を付けます — 例えば、「Knowledge Worker Context」 — そして生成をクリックします。MemoryLakeは3つの値を返します:Key ID、Secret、およびエンドポイントURL。Secretをすぐにコピーしてください;これは一度だけ表示され、後で取得することはできません。
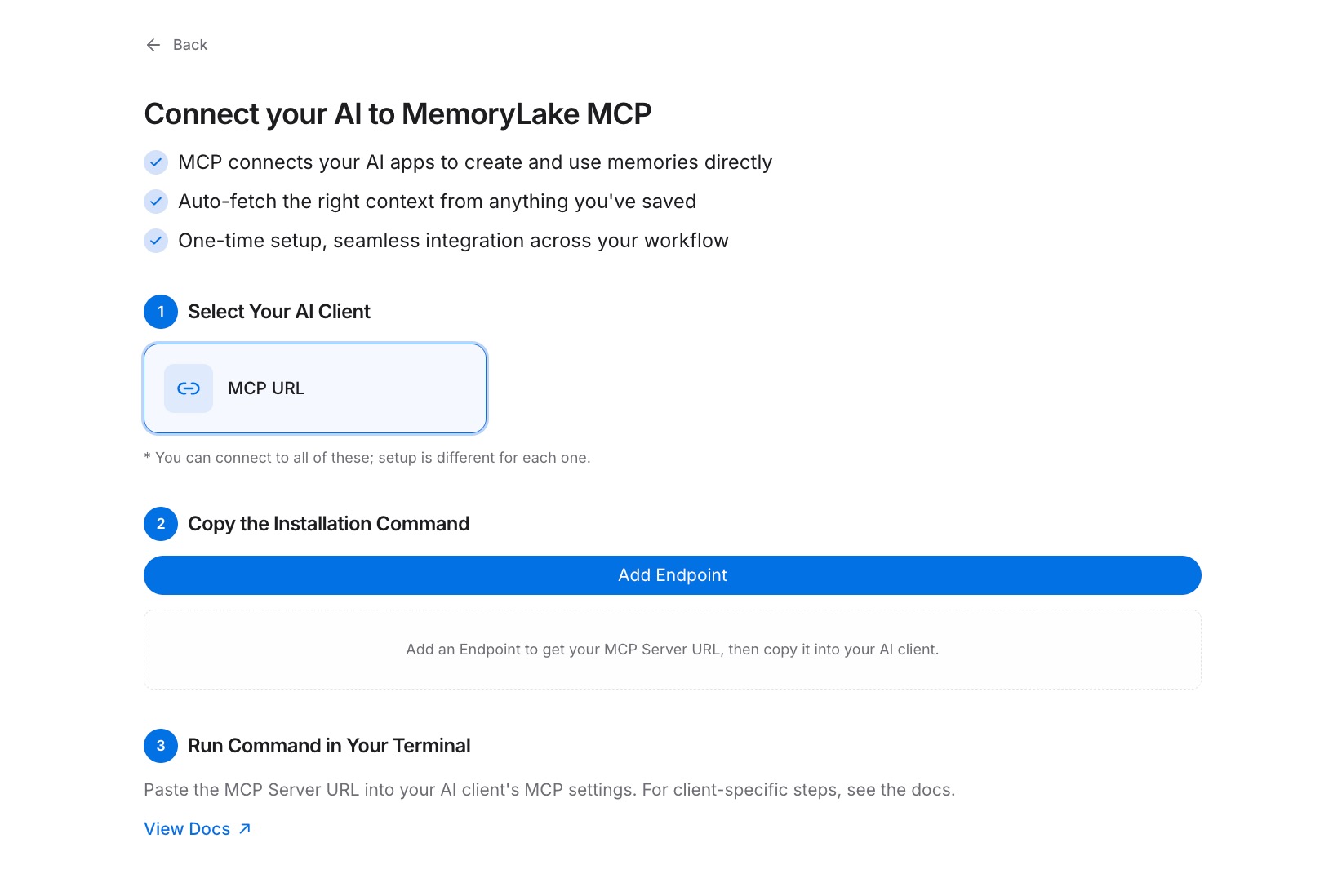
ステップ3:AIツールをMCP経由で接続する
接続したい最初のAIツールでMCP設定を開きます。エンドポイントURLを新しいMCPサーバーとして登録し、Secretを認証のためのBearerトークンとして設定します。設定を保存し、ツールを再起動します。この時点から、ツールは必要に応じてあなたのプロジェクトを読み取ることができます。このステップを使用する他のすべてのAIツールについて繰り返します — 各ツールは同じエンドポイントURLに接続するため、すべてが同じプロジェクトから同じコンテキストを読み取ります。MCP設定ガイドを参照して、完全な設定リファレンスを確認してください。[MemoryLakeを無料で試す]
ツールごとの組み込み記憶とMemoryLakeの比較
| 次元 | ツールごとの組み込み記憶 | MemoryLake |
|---|---|---|
| セッションをまたいで持続する | 変動(しばしば要約される) | はい — 逐語的かつ完全 |
| 他のAIツールで機能する | いいえ — ツールごとにサイロ化 | はい — 1つのプロジェクト、すべてのツール |
| 容量 | 制限または要約 | プロジェクトに応じてスケール |
| バージョン管理 | いいえ | はい(Gitスタイルの履歴) |
| データ所有権 | プラットフォーム保有 | あなたが所有(AES-256、エクスポートまたは削除可能) |
| ベンチマーク | — | LoCoMo #1 — 94.03% |
ヒントとベストプラクティス
- 各記憶エントリに説明的な名前を付ける(例えば、「ライティングスタイル:短い段落、能動態」)ことで、個々のAIツールがプロジェクト内のすべてを読むことなく、正しいルールを取得できるようにします。
- プロジェクトを作業コンテキストごとに分ける — クライアントのエンゲージメント用、内部リサーチ用 — ことで、AIがそのタスクに関連する背景のみを引き出すようにします。
- ブリーフや用語集のような参照ファイルを記憶として貼り付けるのではなく、ドキュメントドライブに保存します。大きな構造化されたコンテンツは、文書として取得する方が良好です。
- 定期的にMCPキーをローテーションするか、キーが誤って共有された場合はすぐにローテーションします — MCPサーバータブで古いキーを取り消し、新しいものを生成します。
トラブルシューティング
- AIツールがMemoryLakeからの記憶を表示しない: エンドポイントURLが生成された通りに正確に入力されていることを確認し、ツールのMCP設定が保存され、ツールが再起動されていることを確認します。
- すべてのクエリで認証エラー: Secretがベアラートークンとして貼り付けられていることを確認し、プレーンAPIキーやユーザー名/パスワードフィールドとしてではないことを確認します。
- 「Secretが見つかりません」というメッセージ: Secretは生成時に一度だけ表示されます。現在のキーをMCPサーバータブで取り消し、新しいものを生成し、ツールの設定でベアラートークンを更新します。
クロスツール記憶層を一度構築し、どこでも使用する
あなたのコンテキストを単一のMemoryLakeプロジェクトに読み込むと、あなたが使用するすべてのAIツールが同じソースを読み取ります — ツールを切り替えるたびにあなたが誰であるかを再説明する必要はありません。