短い答え
MemoryLakeプロジェクトを作成し、事実やファイルをロードし、MCPサーバーエンドポイントを生成し、各AIツールのMCP設定にエンドポイントURLとシークレットをBearerトークンとして貼り付けます。1つの記憶ストア、すべてのAI、セッションを超えて永続的です。
各AIの組み込み記憶がクロスモデル作業に不足している理由
ほとんどのAIツールには何らかの形の記憶が搭載されていますが、それぞれがサイロになっています。ChatGPTの記憶はChatGPTに存在します。ClaudeのプロジェクトノートはGeminiには見えません。CursorのルールはCursorの内部に留まります。あなたのワークフローが2つ以上のツールにまたがると — 1つで草案を作成し、別のものでレビューし、3つ目でコードを実行する — それらは他のツールが知っていることを共有しません。
ギャップは急速に拡大します。ClaudeからChatGPTに切り替えて計算を確認すると、Claudeに1時間前に伝えた制約を知らないのです。Geminiを開いて第二の意見を求めると、数週間前に設定したプロジェクト命名規則については全く知らないのです。すべての引き継ぎは時間を費やし、古いコンテキストに基づいてツールが行動するリスクは現実です。
不足しているのは、どの単一のAIの外側に位置する記憶層です — どのツールでもクエリでき、データを制御できるものです。それがMCPのリソースアクセスパターンが設計されたアーキテクチャのギャップであり、このガイドがカバーする内容です。
始める前に
必要なもの:
- 無料のMemoryLakeアカウント
- コンテキストを共有したいAIツールが少なくとも2つ(例:ChatGPTとClaude Code、またはMCP互換エージェント)
- 永続させたいコンテキスト — 事実、ルール、参照文書(PDF、Word、Excel、PowerPoint、テキスト/Markdown、または画像)
MCPを使用してクロスAI記憶を設定する方法(ステップバイステップ)
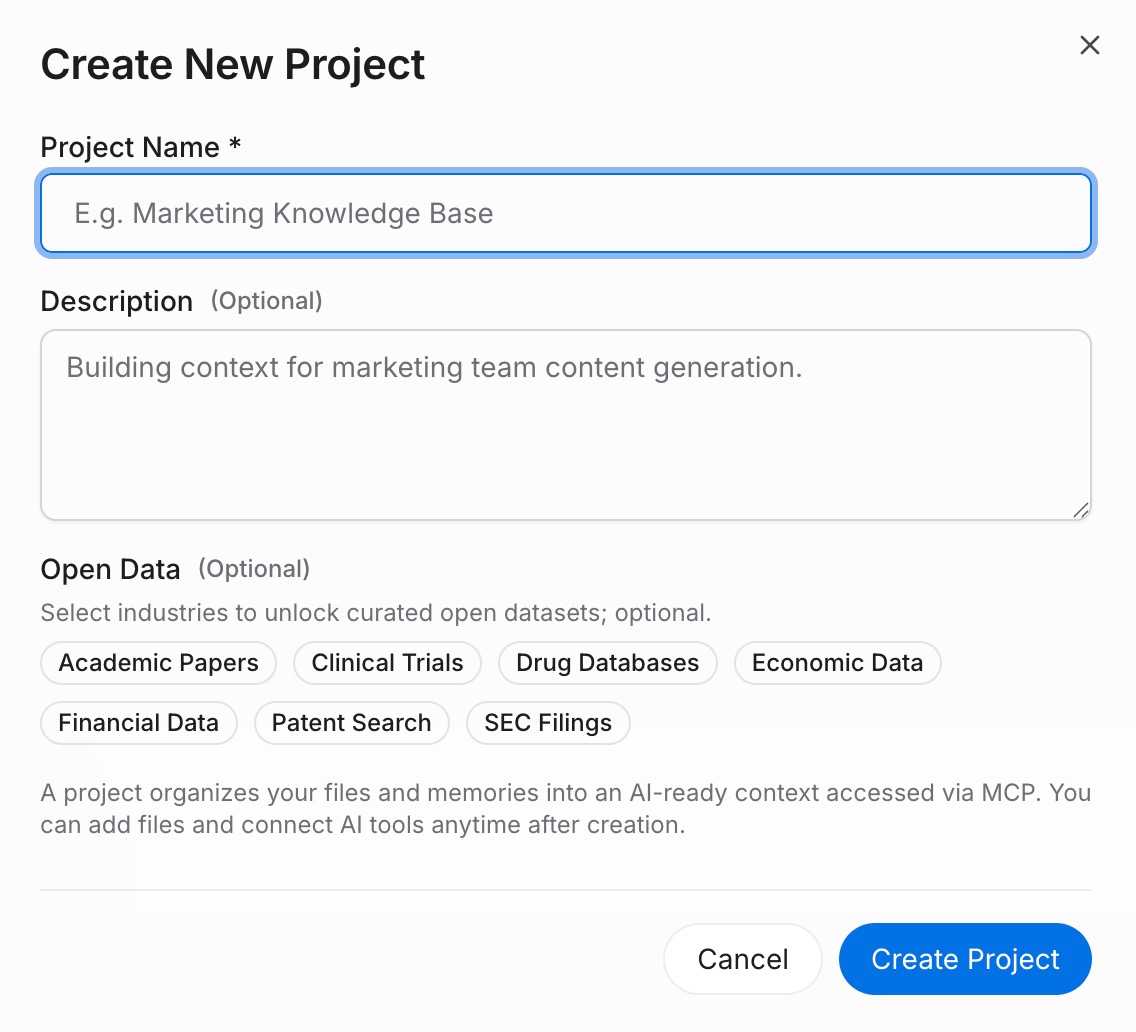
ステップ1:記憶プロジェクトを構築する
MemoryLakeにサインインし、プロジェクト管理を開きます。プロジェクトを作成をクリックし、説明的な名前を付けます — 例えば、「共有AIコンテキスト」やあなたのプロジェクト名です。ドキュメントドライブを開き、アップロードをクリックして参照ファイルを追加します。ドキュメントタブ → ドキュメントを追加 → 確認に進んでプロジェクトに添付します。次に、記憶タブ → 記憶を追加を開いて、AIが常に知っておくべきルール、好み、または事実をキャプチャします → 保存。
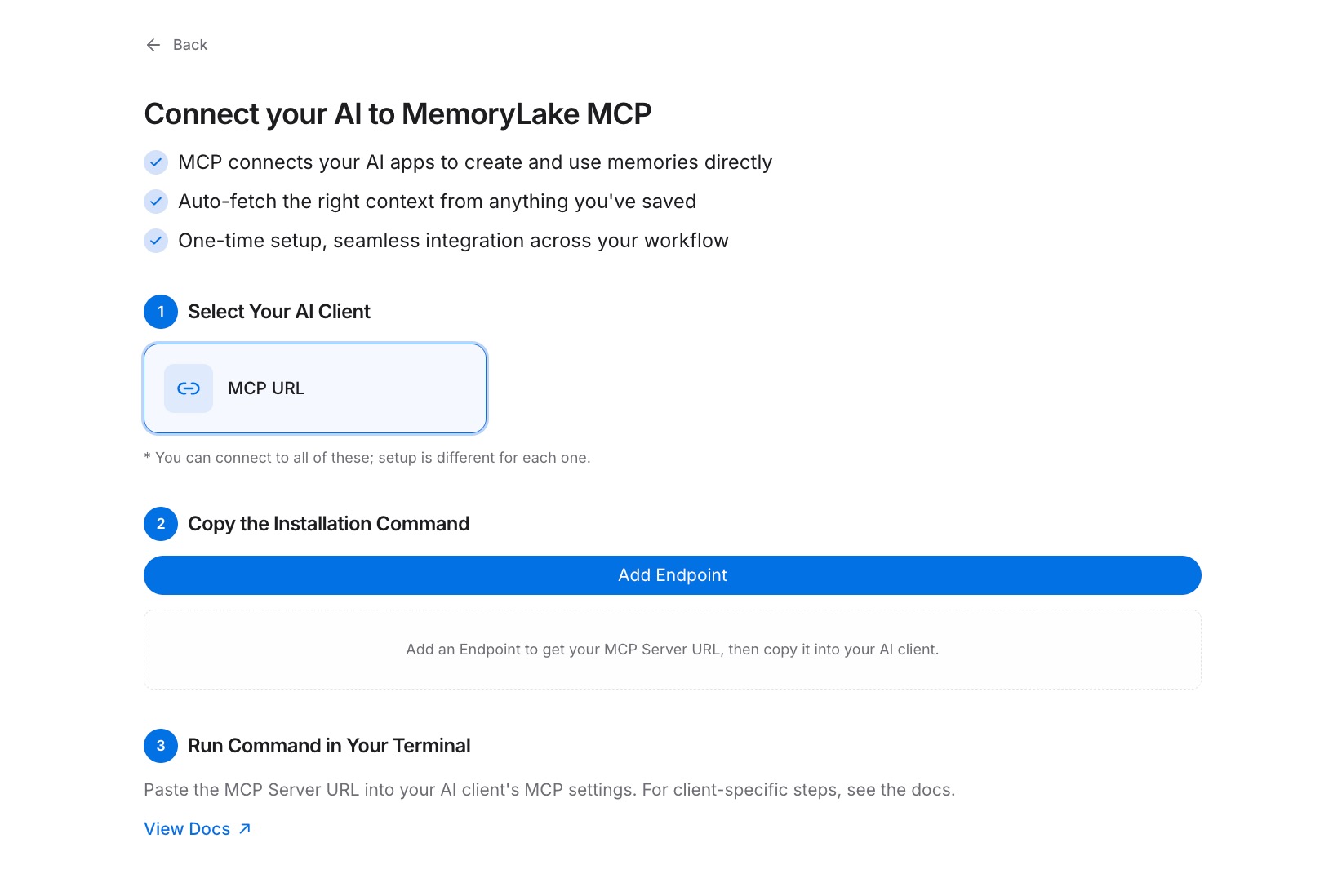
ステップ2:MCPサーバーエンドポイントを生成する
MCPサーバータブ → MCPサーバーを追加に移動します。サーバーにその範囲を反映するラベルを付けます — 例えば、「クロスAI記憶エンドポイント」 — そして生成をクリックします。MemoryLakeは3つの値を返します:キーID、シークレット、およびエンドポイントURL。今すぐシークレットをコピーしてください;これは一度だけ表示されます。ダイアログを閉じる前に、パスワードマネージャーまたはシークレットボールトに保存してください。
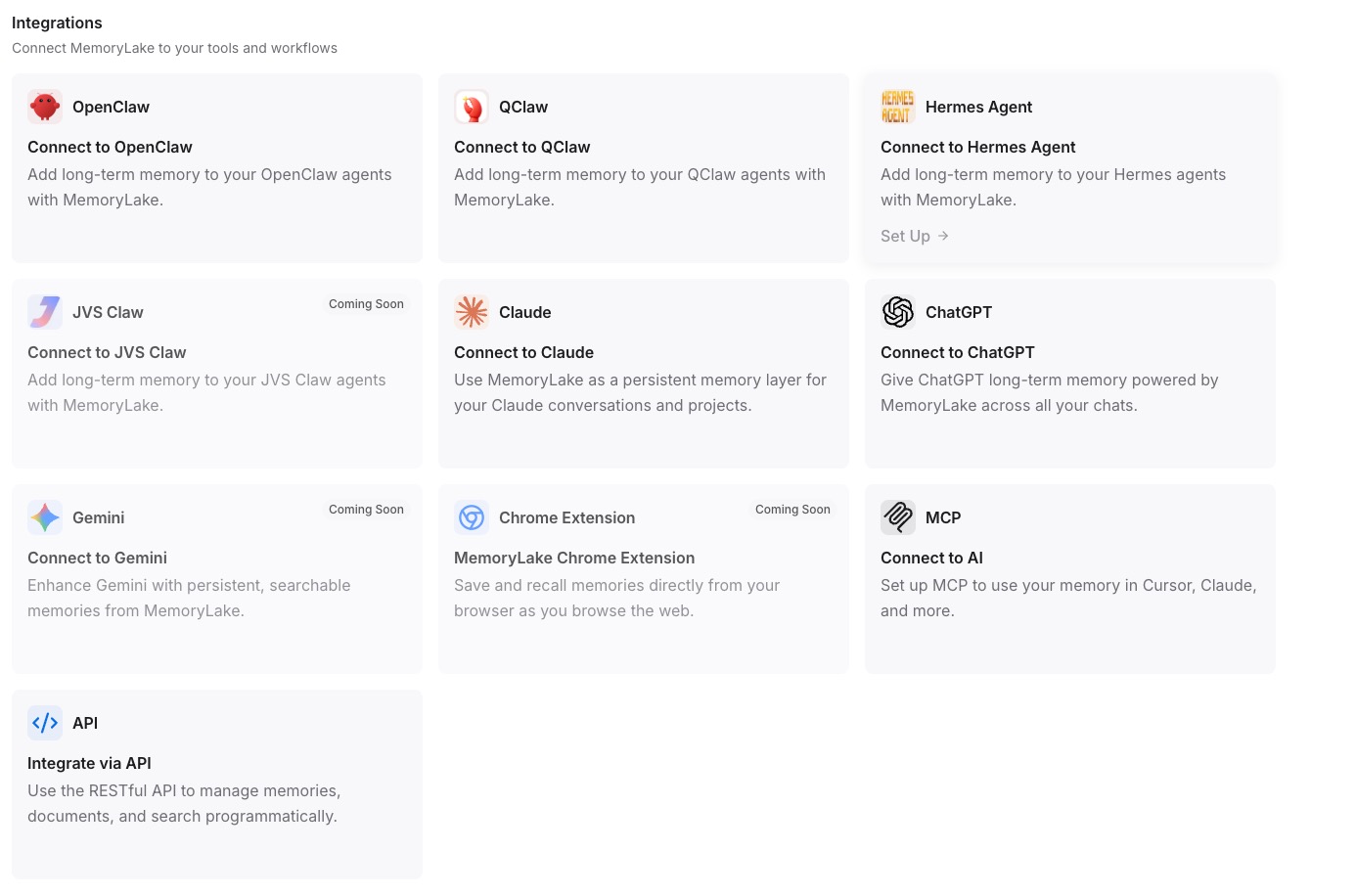
ステップ3:各AIツールをMCP経由で接続する
接続したい各AIツールのMCP設定を開きます。エンドポイントURLをサーバーURLフィールドに貼り付け、シークレットを認証ヘッダーのBearerトークンとして入力します。ワークフロー内のすべてのツールに対して繰り返します — 各ツールは同じMemoryLakeプロジェクトから読み書きします。正確な設定構文については、MCP設定ガイドを参照してください。特にClaude Codeを使用する場合は、Claude Code統合ページに専用の設定手順があります。[MemoryLakeを無料で試す]
AIの組み込み記憶とMemoryLake
| 次元 | ツールごとの組み込み記憶 | MemoryLake |
|---|---|---|
| セッションを超えて持続する | 時々(ツールによって異なる) | はい、常に |
| 他のAI間で機能する | いいえ — ツールごとにサイロ化 | はい — すべてのMCP接続ツール |
| 容量 | 限定(ツール定義) | プロジェクトに応じてスケール |
| バージョン管理 | いいえ | はい(Gitスタイルの履歴) |
| データ所有権 | ツールベンダーが管理 | あなたが所有(AES-256、エクスポート/削除) |
| ベンチマーク | — | LoCoMo #1 — 94.03% |
ヒントとベストプラクティス
- ツールではなくコンテキストドメインで整理する。 プロジェクトをトピックやクライアントに基づいて名付け、コンテンツを最初に作成したAIに基づいて名付けないでください — すべてのツールがすべてのプロジェクトを使用できるべきです。
- 記憶エントリに常設ルールを保持し、ドキュメントドライブに参照資料を保持する。 短い記憶エントリは各クエリで迅速に取得されます;大きな文書はドキュメントドライブに置き、効率的にインデックス化およびチャンク化されます。
- スケジュールに従ってシークレットをローテーションする。 MCPサーバータブで新しいキーを生成し、各ツールの設定を更新し、古い認証情報は保存されたコンテキストに影響を与えることなく機能しなくなります。
- ファイルを更新する際にドキュメントバージョンノートを追加する。 MemoryLakeはGitスタイルの履歴を追跡するため、ドキュメントを置き換える際に簡単なノートを追加することで、AIがどのバージョンに基づいて行動したかを監査しやすくなります。
トラブルシューティング
- 1つのAIが古いコンテキストを見ている間、別のAIが更新を見ている: すべてのツールが同じエンドポイントURLとプロジェクトIDを指していることを確認してください。URLの不一致は異なるプロジェクトを読み取っていることを意味します。
- シークレットをローテーションした後に認証が拒否される: 古いBearerトークンはローテーション時に無効になります。MCPサーバータブで生成された新しいシークレットで各ツールのMCP設定を更新してください。
- 最初の接続時に「シークレットが見つかりません」エラー: シークレットは生成時に一度だけ表示されました。既存のキーを無効にし、MCPサーバータブで再度生成をクリックして新しい認証情報を発行します。
1つの記憶層、すべてのAI
ツールを切り替えるたびに自己紹介を繰り返すのをやめましょう。一度接続すれば、ワークフロー内のすべてのAIが同じ永続的なコンテキストを共有します。