简短答案
知识工作者可以通过创建MemoryLake项目来设置跨工具AI记忆,将他们的上下文加载到其中(文档、规则、偏好),生成一个MCP服务器端点,并将每个AI工具连接到该端点。每个工具读取相同的项目——切换工具时无需重新解释上下文。
为什么每个AI工具的内置记忆不够用
大多数AI工具提供某种形式的会话历史或轻量级记忆功能,但每个工具都是一个孤岛。您在ChatGPT中建立的上下文不会传递到Claude。您在编码代理中设置的规则不会出现在研究工具中。您最终维护多个不一致的“您是谁以及您需要什么”的副本——它们不可避免地会失去同步。
也没有共享所有权。每个工具以自己的方式总结或解释您的上下文,这意味着您写下的精确指令会被改写、删减或丢弃。当您在项目中切换工具时,您会立即感受到成本:五分钟解释您的限制,再花两分钟澄清您的术语,然后是当AI假设错误时不可避免的纠正。
对于一个在一个下午同时使用三到四个AI工具进行研究、写作、数据分析和沟通的知识工作者来说,这种摩擦迅速累积。真正的差距不在于任何一个工具的记忆——而在于没有单一的真相来源存在于您的整体上下文中。
开始之前
您需要:
- 一个免费的MemoryLake账户
- 至少一个支持MCP的AI工具(Claude Desktop、Cursor或任何其他兼容MCP的客户端)
- 您最常重复的上下文——项目简介、风格规则、偏好或参考文件(PDF、Word、Excel、PowerPoint、Markdown或图像)
如何为知识工作者设置跨工具记忆(逐步指南)
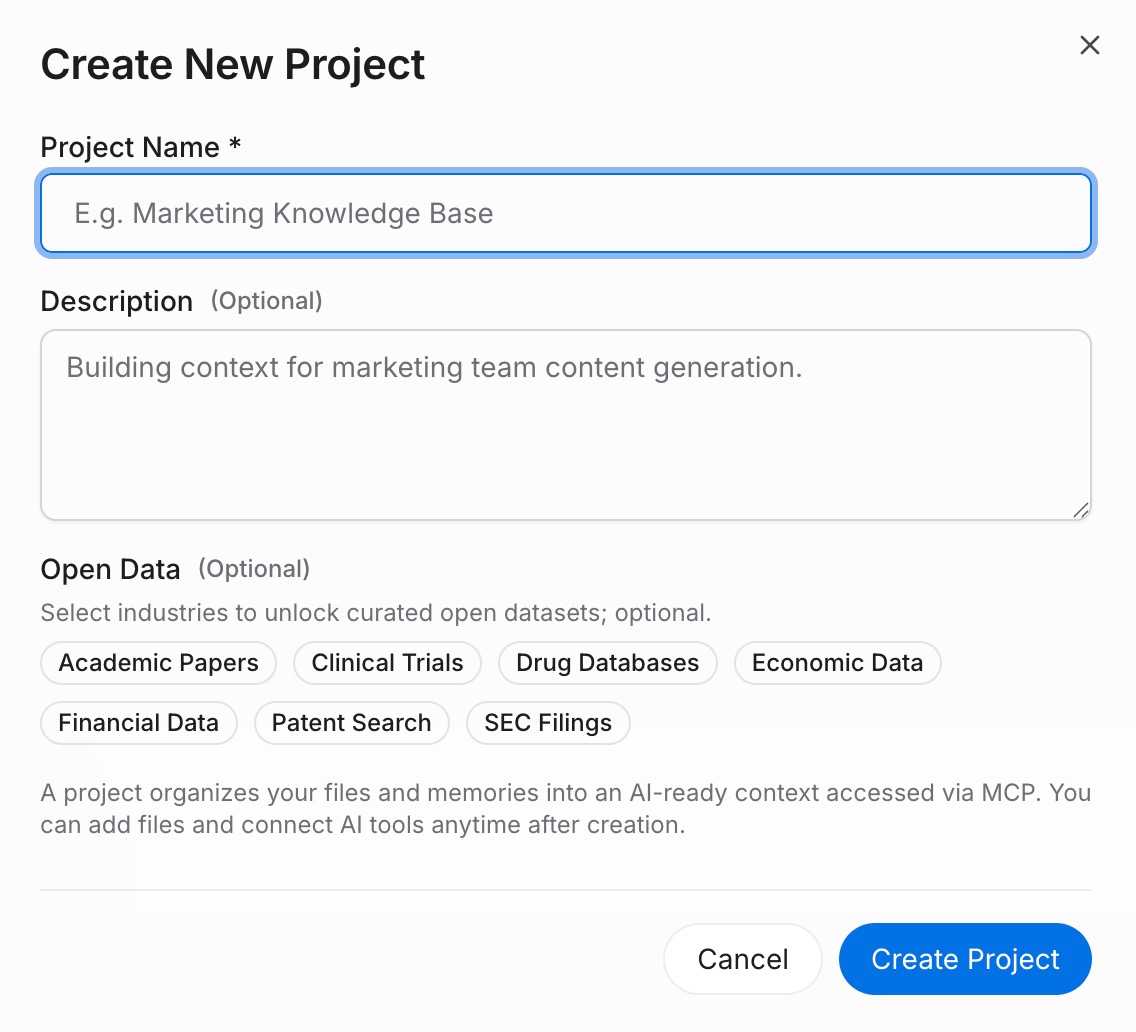
第一步:构建记忆项目
登录MemoryLake并转到项目管理。点击创建项目并给它一个清晰的名称——例如,“工作上下文2026”。在项目内,打开文档驱动并点击上传以添加参考文件,例如项目简介、风格指南或研究笔记。然后打开文档标签,点击添加文档,点击确认将上传的文件附加到项目中。接下来,打开记忆标签,点击添加记忆,输入一个常规规则或偏好(例如,您偏好的响应格式、重复的约束或关键术语),然后点击保存。对每个您通常在引导AI工具时重复的规则重复此操作。
第二步:生成MCP服务器端点
在项目内,打开MCP服务器标签并点击添加MCP服务器。给服务器一个描述性的名称——例如,“知识工作者上下文”——然后点击生成。MemoryLake返回三个值:密钥ID、密钥和端点URL。立即复制密钥;它只显示一次,无法在之后检索。
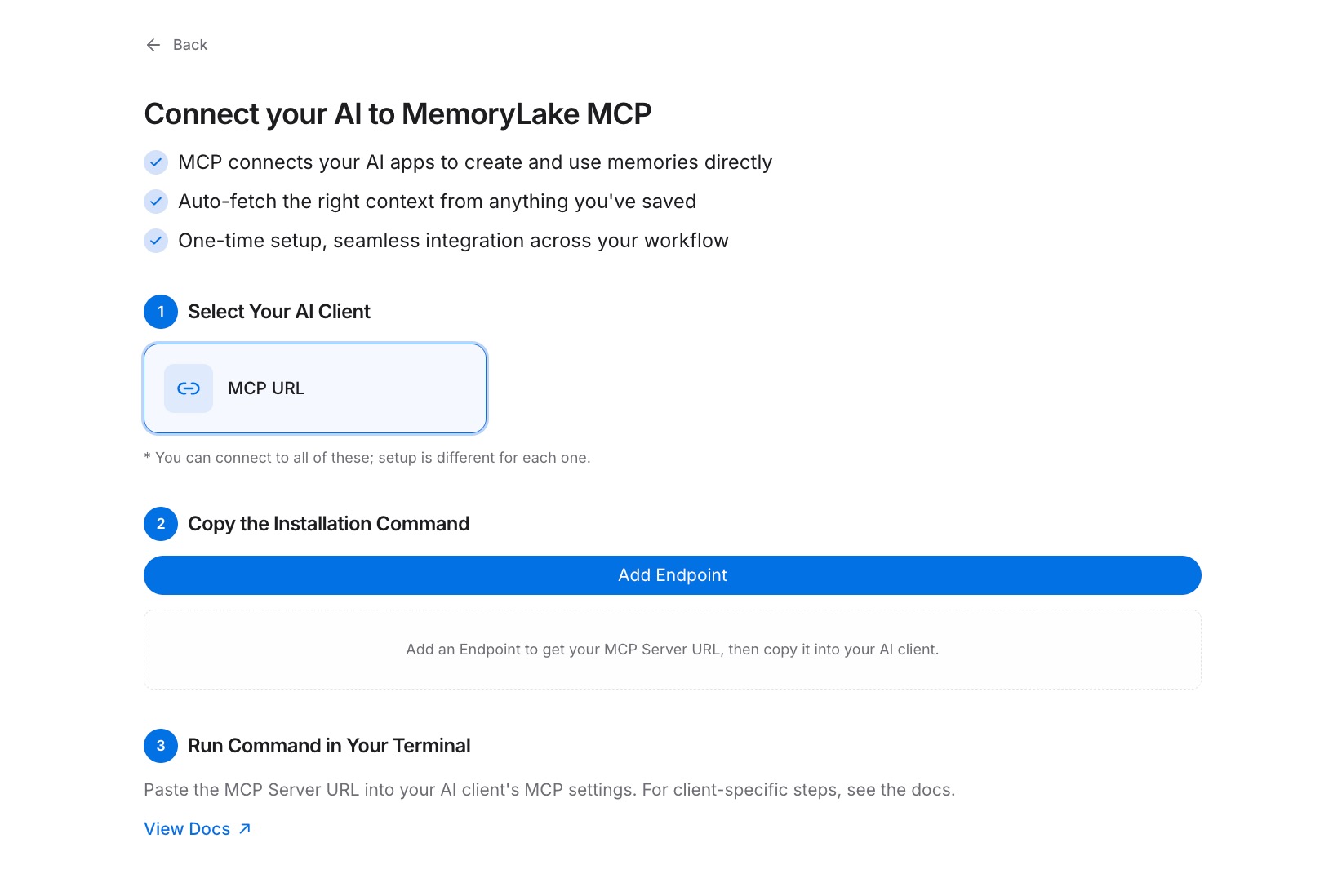
第三步:通过MCP连接您的AI工具
打开您想要首先连接的AI工具中的MCP配置。将端点URL注册为新的MCP服务器,并将密钥设置为身份验证的Bearer令牌。保存配置并重启工具。从此时起,该工具可以按需读取您的项目。对您使用的每个其他AI工具重复此步骤——每个工具连接到相同的端点URL,因此它们都从相同的项目中读取相同的上下文。请参阅MCP设置指南以获取完整的配置参考。[免费试用MemoryLake]
每个工具的内置记忆与MemoryLake
| 维度 | 每个工具的内置记忆 | MemoryLake |
|---|---|---|
| 跨会话持久 | 变化(通常被总结) | 是——逐字且完整 |
| 在其他AI工具中工作 | 否——每个工具孤立 | 是——一个项目,所有工具 |
| 容量 | 有限或总结 | 随您的项目扩展 |
| 版本控制 | 否 | 是(Git风格历史) |
| 数据所有权 | 平台持有 | 您拥有(AES-256,导出或删除) |
| 基准 | — | LoCoMo #1 — 94.03% |
提示与最佳实践
- 为每个记忆条目命名时要描述性(例如,“写作风格:短段落,主动语态”),以便各个AI工具可以在不阅读项目中所有内容的情况下检索正确的规则。
- 按工作上下文分隔项目——一个用于客户参与,一个用于内部研究——以便AI仅提取与当前任务相关的背景。
- 将参考文件如简介和术语表存储在文档驱动中,而不是作为记忆粘贴;较大的结构化内容作为文档检索效果更好。
- 定期轮换您的MCP密钥,或在密钥意外共享时立即轮换——在MCP服务器标签中撤销旧密钥并生成替换密钥。
故障排除
- AI工具未显示MemoryLake的记忆:确认端点URL输入与生成时完全一致,并且工具的MCP配置已保存且工具已重启。
- 每个查询的身份验证错误:验证密钥是否作为Bearer令牌粘贴,而不是作为普通API密钥或用户名/密码字段。
- “未找到密钥”消息:密钥仅在生成时显示一次。在MCP服务器标签中撤销当前密钥并生成新密钥,然后更新您工具配置中的Bearer令牌。
一次构建您的跨工具记忆层,随处使用
将您的上下文加载到一个MemoryLake项目中,您使用的每个AI工具都读取相同的来源——不再每次切换工具时重新解释您是谁。