简短答案
创建一个MemoryLake项目,加载您的事实和文件,生成一个MCP服务器端点,然后将端点URL和密钥粘贴到每个AI工具的MCP配置中作为Bearer令牌。一个记忆存储,所有AI,跨会话持久。
为什么每个AI的内置记忆在跨模型工作中不够用
大多数AI工具都带有某种形式的记忆,但每个都是一个孤岛。ChatGPT的记忆存在于ChatGPT中。Claude的项目笔记对Gemini是不可见的。Cursor的规则保留在Cursor内部。当您的工作流程跨越两个或更多工具——在一个工具中草拟,在另一个工具中审查,在第三个工具中执行代码——它们之间没有共享彼此所知道的内容。
这种差距迅速加大。您从Claude切换到ChatGPT以验证计算,而它不知道您一个小时前告诉Claude的约束。您打开Gemini以获取第二意见,而它对您几周前设置的项目命名约定一无所知。每次交接都耗费时间,工具在过时上下文上操作的风险是真实存在的。
缺失的是一个位于任何单一AI 之外 的记忆层——任何工具都可以查询的层,您控制数据的层。这就是MCP资源访问模式旨在填补的架构差距,也是本指南所涵盖的内容。
开始之前
您需要:
- 一个免费的MemoryLake账户
- 至少两个您希望共享上下文的AI工具(例如,ChatGPT和Claude Code,或任何兼容MCP的代理)
- 您希望持久化的上下文——事实、规则、参考文档(PDF、Word、Excel、PowerPoint、文本/Markdown或图像)
如何使用MCP设置跨AI记忆(逐步)
步骤1:构建一个记忆项目
登录MemoryLake并打开项目管理。点击创建项目并给它一个描述性的名称——例如,“共享AI上下文”或您的项目名称。打开文档驱动并点击上传以添加任何参考文件。转到文档标签 → 添加文档 → 确认以将它们附加到项目。然后打开记忆标签 → 添加记忆以捕获您的AI应该始终知道的规则、偏好或事实 → 保存。
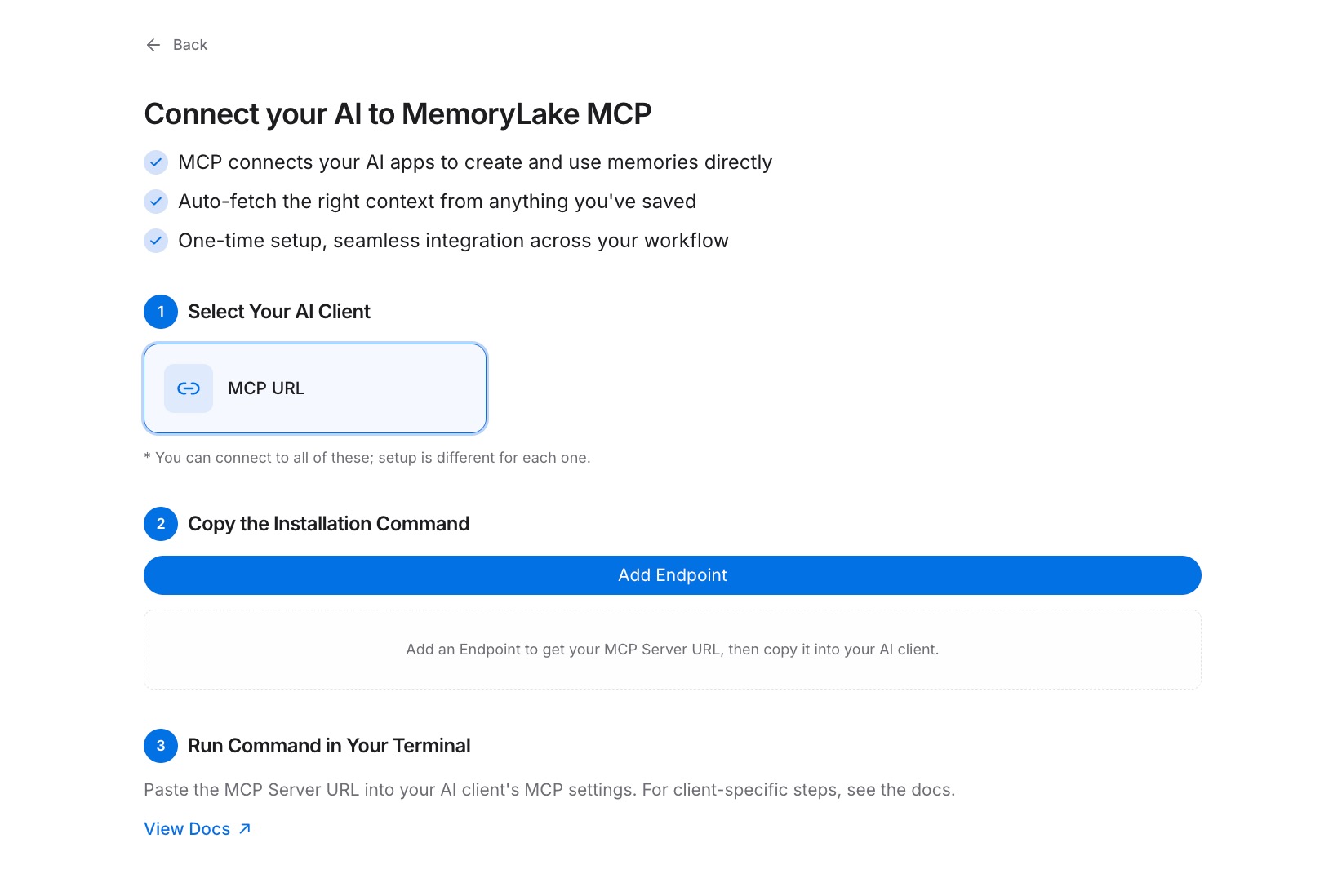
步骤2:生成一个MCP服务器端点
导航到MCP服务器标签 → 添加MCP服务器。给服务器一个反映其范围的标签——例如,“跨AI记忆端点”——然后点击生成。MemoryLake返回三个值:密钥ID、密钥和端点URL。现在复制密钥;它只显示一次。在关闭对话框之前,将其存储在您的密码管理器或秘密库中。
步骤3:通过MCP连接每个AI工具
打开您想要连接的每个AI工具的MCP配置。将端点URL粘贴到服务器URL字段中,并在身份验证头中输入密钥作为Bearer令牌。对您工作流程中的每个工具重复此操作——每个工具现在都可以从同一个MemoryLake项目中读取和写入。请参阅MCP设置指南以获取确切的配置语法。如果您专门使用Claude Code,Claude Code集成页面有专门的设置步骤。[免费试用MemoryLake]
AI内置记忆与MemoryLake
| 维度 | 每工具内置记忆 | MemoryLake |
|---|---|---|
| 跨会话持久 | 有时(因工具而异) | 是,总是 |
| 在其他AI之间工作 | 否——每工具孤立 | 是——任何连接MCP的工具 |
| 容量 | 有限(工具定义) | 随您的项目扩展 |
| 版本控制 | 否 | 是(Git风格历史) |
| 数据所有权 | 工具供应商控制 | 您拥有它(AES-256,导出/删除) |
| 基准 | — | LoCoMo #1 — 94.03% |
提示与最佳实践
- 按上下文领域组织,而不是按工具。 根据主题或客户命名您的项目,而不是根据首次创建内容的AI——每个工具都应该能够使用每个项目。
- 将常规规则保留在记忆条目中,将参考材料保留在文档驱动中。 短记忆条目在每次查询时快速检索;大型文档应放在文档驱动中,以便高效索引和分块。
- 定期轮换密钥。 在MCP服务器标签中生成一个新密钥,更新每个工具的配置,旧凭证在不影响存储上下文的情况下停止工作。
- 更新文件时添加文档版本说明。 因为MemoryLake跟踪Git风格的历史,替换文档时添加简短说明使得审计AI所依据的版本变得容易。
故障排除
- 一个AI看到过时的上下文,而另一个看到更新: 确认所有工具指向相同的端点URL和项目ID。URL不匹配意味着它们正在读取不同的项目。
- 轮换密钥后身份验证被拒绝: 旧的Bearer令牌在轮换时被撤销。使用在MCP服务器标签中生成的新密钥更新每个工具的MCP配置。
- 首次连接时出现“未找到密钥”错误: 密钥在生成时只显示一次。撤销现有密钥并在MCP服务器标签中再次点击生成以发放新的凭证。
一个记忆层,所有AI
停止在每次切换工具时重新介绍自己。连接一次,您工作流程中的每个AI共享相同的持久上下文。