简短回答
每个 AI 聊天会话默认以空上下文窗口开始,因此工具在会话结束时会忘记所有内容。将您的规则、背景和参考文件存储在 MemoryLake 项目中,通过 MCP 公开,任何您连接的 AI 工具都可以按需读取您的上下文——无需重新解释,无需复制粘贴,唯一真实的来源。
为什么 AI 工具的内置上下文处理不够好
大多数 AI 工具以两种方式处理上下文:它们仅在活动会话中保持上下文,或者存储与单个帐户相关的压缩摘要。这两种方法都会造成相同的日常挫败感。
仅会话上下文是最常见的。在 ChatGPT、Claude、Gemini 或几乎任何 AI 编码助手中打开一个新的聊天,您就会从头开始。该工具没有记录您昨天、上周或去年告诉它的内容。您每次都要重新介绍自己,粘贴您的风格指南,重新解释限制——每一次都是如此。
帐户级摘要在边际上有所帮助,但它们是浅显且孤立的。摘要属于一个平台上的一个产品。切换工具——例如,从 ChatGPT 切换到 Claude 再到编码代理——每个工具都在运行完全独立的记忆。您的专业知识、偏好和项目上下文分散在三个不同的地方,所有地方都略微不同步。
根本问题不在于任何一个工具的质量。问题在于架构。AI 工具默认设计为无状态,它们的可选记忆功能是附加的,彼此之间不进行通信。解决此问题需要一个位于工具外部的层——一个所有工具都可以读取的单一持久存储。
开始之前
您需要:
- 一个免费的 MemoryLake 帐户
- 至少一个支持 MCP 的 AI 工具(Claude Desktop、Cursor、OpenClaw、Hermes 或任何其他 MCP 客户端)
- 您的上下文准备好加载——文档(PDF、Word、Excel、PowerPoint、Markdown 或图像)以及您不断重复的任何固定规则或偏好
如何停止向您的 AI 重新解释上下文(逐步指南)
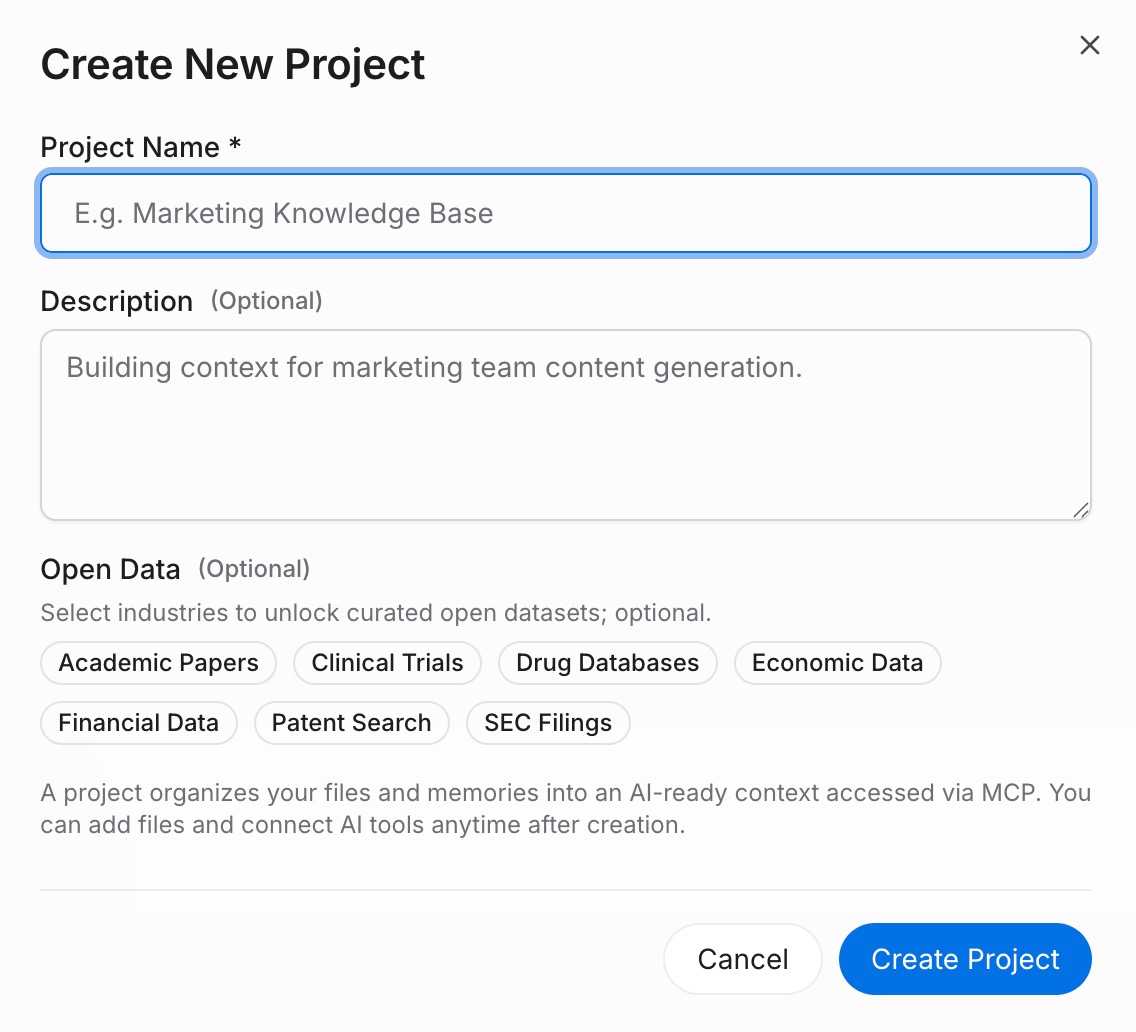
第一步:构建一个记忆项目
登录 MemoryLake,进入 项目管理。点击 创建项目,并给它一个描述性的名称——例如 "我的 AI 上下文" 或 "工作背景"。在项目内部,打开 文档驱动,点击 上传 添加参考文件,例如您的简历、风格指南或技术规格。然后转到 文档选项卡 → 添加文档 → 确认 将它们附加到项目中。对于固定规则——您的沟通风格、重复指令、个人偏好——使用 记忆选项卡 → 添加记忆 → 保存 每个规则。将记忆选项卡视为您 AI 的永久简报笔记。
第二步:生成一个 MCP 服务器端点
导航到 MCP 服务器选项卡,点击 添加 MCP 服务器。命名服务器(例如,"个人上下文层"),然后点击 生成。MemoryLake 创建一个 密钥 ID、一个 密钥 和一个 端点 URL。立即复制 密钥——它只显示一次。在关闭面板之前将其安全存储。
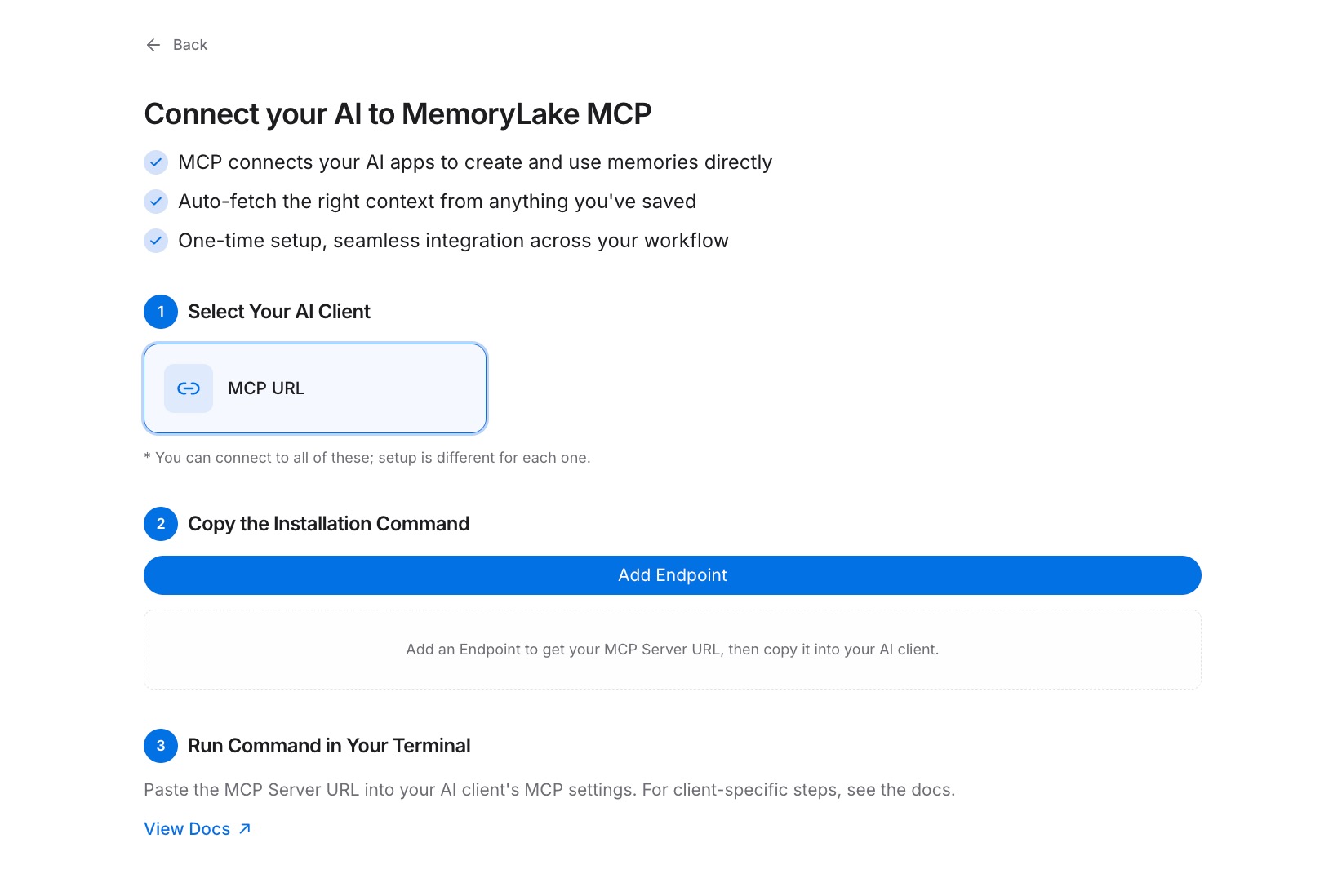
第三步:通过 MCP 连接您的 AI 工具
在您选择的 AI 工具中打开 MCP 配置,并将 MemoryLake 注册为 MCP 服务器。将 端点 URL 粘贴为服务器地址,并将 密钥 设置为身份验证的 Bearer token。保存配置并重启工具。从此时起,该工具按需读取您存储的上下文。对您使用的每个 AI 工具重复此步骤——它们都指向相同的项目,因此您的上下文在各处保持一致。请参阅 MCP 设置指南 获取确切的配置格式。[免费试用 MemoryLake]
AI 内置上下文与 MemoryLake
| 维度 | AI 内置上下文 | MemoryLake |
|---|---|---|
| 跨会话持久化 | 否(或部分摘要) | 是——完整逐字存储 |
| 跨其他 AI 工作 | 否——每个产品孤立 | 是(ChatGPT、Claude、Gemini、任何 MCP 工具) |
| 容量 | 有限(会话或薄摘要) | 完整文档 + 离散记忆 |
| 版本控制 | 否 | 是(Git 风格历史) |
| 数据所有权 | 平台持有 | 您拥有它(AES-256,导出或删除) |
| 基准 | — | LoCoMo #1 — 94.03% |
提示与最佳实践
- 将记忆条目写成直接指令("始终使用英国英语" 或 "我是一家金融科技公司的高级后端工程师"),而不是被动描述——AI 工具对指令的反应比解析个人资料更可靠。
- 为不同的上下文创建单独的项目。"自由职业客户" 项目和 "个人学习" 项目可以防止不相关的上下文在错误的对话中出现。
- 将参考文档——架构图、品牌指南、技术规格——加载到文档驱动中,而不是在每个聊天中粘贴它们。该工具在需要时检索它们,而不会膨胀您的上下文窗口。
- 每几周审核一次您的记忆选项卡。过时的规则与当前规则竞争,删除陈旧条目可以保持检索的敏锐。
故障排除
- AI 工具似乎没有使用任何存储的上下文: 验证 MCP 服务器条目是否已保存在工具的配置中,并确保在添加后重启了工具。
- 身份验证被拒绝: 确认密钥是否完全按复制的内容输入(没有前导或尾随空格),并且它被配置为 Bearer token,而不是基本密码。
- "未找到密钥" 或凭证错误: 密钥只显示一次。如果丢失,请转到 MCP 服务器选项卡,撤销现有服务器,然后再次点击生成以发放新的密钥 ID、密钥和端点 URL。
再也不要从头开始对话
一个项目,一个端点,所有 AI 工具都在同一页面上。只需设置一次,您花费数月构建的上下文将随您而行。