简短答案
每个主要的 AI 工具都将上下文存储在自己的私有孤岛中,因此切换工具意味着重新开始。要在它们之间同步记忆,请创建一个单一的 MemoryLake 项目,将其公开为 MCP 服务器端点,并将每个工具指向该端点——您的偏好、规则和文档将成为每个工具按需读取的共享来源。
为什么每个 AI 的内置记忆无法满足跨工具工作流的需求
内置的记忆功能是围绕一个工具、一个账户设计的。ChatGPT 记住您告诉 ChatGPT 的事情。Claude 的聊天记忆保留在 Claude 中。Cursor 的上下文保留在您的编辑器中。当您在它们之间移动时,您什么也不带。
除了孤岛化,记忆模型也不同:一些工具进行总结(失去精确性),一些使用向量搜索(失去结构),还有一些在会话结束后简单地清除窗口。没有共享该状态的标准,没有版本历史,也没有办法审计每个工具实际上对您的了解。
实际成本迅速累积。重新粘贴系统提示、重新上传参考文档、重新指定相同的代码风格指南——这些不是边缘案例,而是任何运行多工具工作流的人的常态。而且,由于每个工具的记忆是由平台持有的,您无法保证它的持久性,无法导出它,也没有补救措施如果该功能被弃用。
跨工具的记忆层从根本上解决了这个问题:一个项目包含所有内容,所有支持 MCP 的工具都可以直接从中读取。
开始之前
您需要:
- 一个免费的 MemoryLake 账户
- 至少一个接受 MCP 服务器连接的 AI 工具(Claude Desktop、Cursor、Copilot 或任何兼容 MCP 的客户端)
- 您在工具之间反复提及的上下文——规则、风格指南、项目笔记或参考文件(PDF、Word、Excel、PowerPoint、Markdown 或图像)
如何在每个工具之间同步您的 AI 记忆(逐步指南)
第一步:构建一个记忆项目
登录 MemoryLake,进入 项目管理。点击 创建项目,给它一个反映其范围的名称——"共享 AI 上下文" 或 "工作规则" 都很好。打开 文档驱动器,点击 上传 添加您的参考文件,然后导航到 文档标签 → 添加文档 → 确认 将它们附加到项目中。对于不在文件中的固定规则和偏好,打开 记忆标签 → 添加记忆,输入规则,然后点击 保存。对您在每个新聊天中粘贴的每个上下文重复此操作。
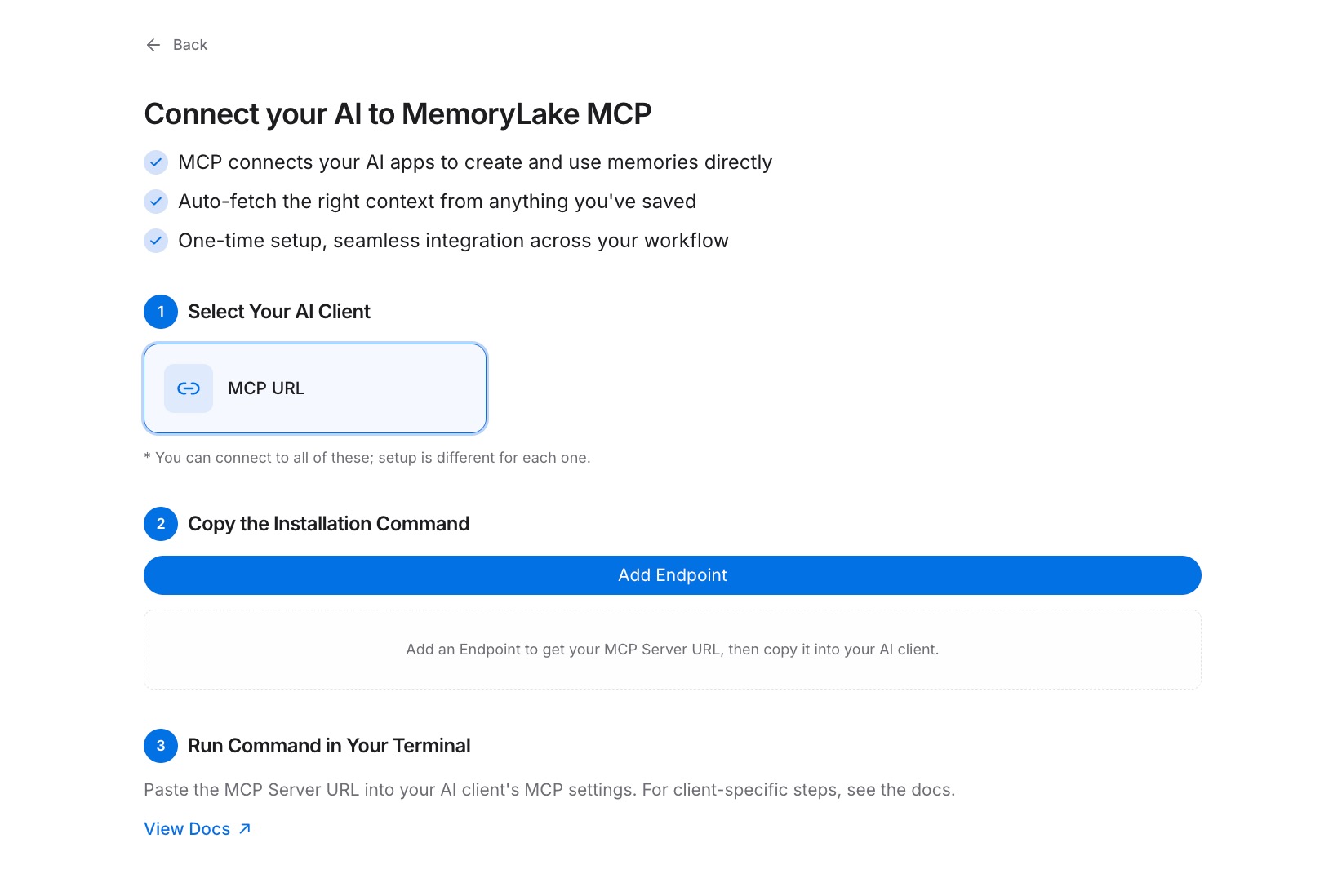
第二步:生成 MCP 服务器端点
导航到 MCP 服务器标签 → 添加 MCP 服务器,并为服务器命名(例如,"跨工具记忆")。点击 生成。MemoryLake 返回三个值:密钥 ID、密钥和 端点 URL。立即复制 密钥——它只显示一次,无法后续检索。
第三步:通过 MCP 连接每个工具
在每个 AI 工具的 MCP 配置面板中,将 端点 URL 注册为 MCP 服务器,并将 密钥 设置为 Bearer token 进行身份验证。保存后重启工具。请参阅 MCP 设置指南 以获取确切的配置参考。连接后,该工具按需查询您的项目——您连接到同一端点的每个其他工具读取相同的上下文,无需复制或同步。[免费试用 MemoryLake]
每个工具的记忆与 MemoryLake 共享层
| 维度 | 每个工具的内置记忆 | MemoryLake 共享层 |
|---|---|---|
| 会话间持久化 | 不同——一些工具会清除它 | 是——存储在您的项目中 |
| 在其他 AI 工具中工作 | 否——按平台孤立 | 是——一个项目,任何 MCP 工具 |
| 容量 | 受每个平台限制 | 随着您的项目扩展 |
| 版本控制 | 无 | 是(Git 风格历史) |
| 数据所有权 | 平台持有 | 您拥有它(AES-256,导出或删除) |
| 基准 | — | LoCoMo #1 — 94.03% |
提示与最佳实践
- 每个不同的上下文保持一个项目——一个 "工作" 项目和一个 "个人写作" 项目可以防止 ChatGPT 将您的 Rust 代码约定拉入旅行行程中。
- 使用 记忆标签 来获取您希望精确检索的规则(工具偏好、格式标准),使用 文档标签 来获取您希望 AI 搜索的文件。
- 当您更新规则时,编辑现有的记忆条目,而不是添加重复项——冲突的条目会混淆检索。
- 一旦密钥被泄露,立即撤销并重新生成;旧的 Bearer token 会立即停止工作,您可以在不重建项目的情况下发出新的。
故障排除
- 工具报告无法访问 MCP 服务器: 验证端点 URL 是否粘贴无尾随空格,并确保在重启工具之前保存了 MCP 条目。
- 身份验证被拒绝: 确认密钥作为 Bearer token 输入(而不是用户名或 API 密钥字段),且没有额外的空格。
- 关闭设置屏幕后出现 "未找到密钥": 密钥只显示一次。打开 MCP 服务器标签,撤销该条目,然后点击 添加 MCP 服务器 → 生成 以发出新的密钥。
一个项目,所有工具,无需重新解释
设置一个共享的 MemoryLake 项目,您的上下文将随您进入每个打开的 AI 工具——不再需要在每个新聊天中粘贴相同的规则。