간단한 답변
지식 근로자는 MemoryLake 프로젝트를 생성하고, 그 안에 자신의 맥락(문서, 규칙, 선호도)을 로드하고, MCP 서버 엔드포인트를 생성한 다음, 각 AI 도구를 해당 엔드포인트에 연결하여 크로스 툴 AI 기억을 설정할 수 있습니다. 모든 도구는 동일한 프로젝트를 읽습니다 — 도구를 전환할 때 맥락을 다시 설명할 필요가 없습니다.
각 AI 도구의 내장 기억이 부족한 이유
대부분의 AI 도구는 세션 기록이나 경량 기억 기능을 제공하지만, 각 도구는 고립되어 있습니다. ChatGPT 내에서 구축한 맥락은 Claude로 이동하지 않습니다. 코딩 에이전트에서 설정한 규칙은 연구 도구에 나타나지 않습니다. 결국 "당신이 누구인지와 무엇이 필요한지"의 여러 불일치하는 복사본을 유지하게 되며, 이들은 불가피하게 동기화에서 벗어납니다.
또한 공유 소유권이 없습니다. 각 도구는 자신의 방식으로 맥락을 요약하거나 해석하므로, 당신이 작성한 정확한 지침이 바뀌거나 잘리거나 폐기됩니다. 프로젝트 중간에 도구를 전환할 때 즉시 비용을 느끼게 됩니다: 제약 조건을 설명하는 데 5분, 용어를 명확히 하는 데 2분, 그리고 AI가 잘못된 것을 가정할 때 불가피한 수정이 필요합니다.
연구, 글쓰기, 데이터 분석 및 커뮤니케이션을 세 개 또는 네 개의 AI 도구로 동시에 처리하는 지식 근로자에게는 이러한 마찰이 빠르게 누적됩니다. 진정한 격차는 어떤 도구의 기억이 아니라, 전체 맥락에 대한 단일 진실의 출처가 존재하지 않는 것입니다.
시작하기 전에
다음이 필요합니다:
- 무료 MemoryLake 계정
- MCP를 지원하는 최소 하나의 AI 도구(Claude Desktop, Cursor 또는 기타 MCP 호환 클라이언트)
- 가장 자주 반복하는 맥락 — 프로젝트 브리프, 스타일 규칙, 선호도 또는 참조 파일(PDF, Word, Excel, PowerPoint, Markdown 또는 이미지)
지식 근로자를 위한 크로스 툴 기억 설정 방법 (단계별)
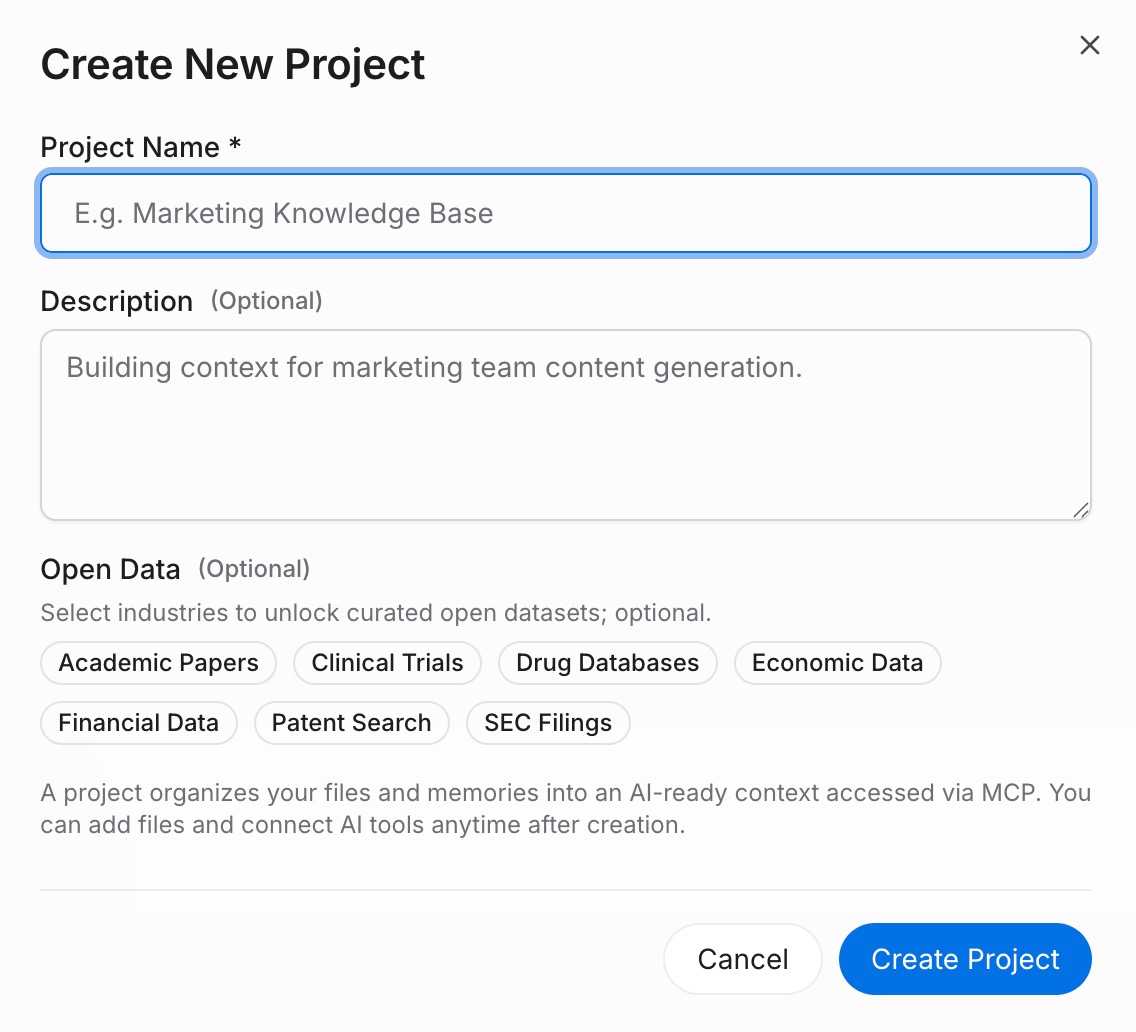
단계 1: 기억 프로젝트 구축
MemoryLake에 로그인하고 프로젝트 관리로 이동합니다. 프로젝트 생성을 클릭하고 명확한 이름을 지정합니다 — 예를 들어, "작업 맥락 2026." 프로젝트 내에서 문서 드라이브를 열고 업로드를 클릭하여 프로젝트 브리프, 스타일 가이드 또는 연구 노트와 같은 참조 파일을 추가합니다. 그런 다음 문서 탭을 열고 문서 추가를 클릭한 후 확인을 클릭하여 업로드한 파일을 프로젝트에 첨부합니다. 다음으로 기억 탭을 열고 기억 추가를 클릭한 후, 규칙이나 선호도를 입력하고(예: 선호하는 응답 형식, 반복 제약 조건 또는 주요 용어) 저장을 클릭합니다. AI 도구를 온보딩할 때 일반적으로 반복하는 각 규칙에 대해 이 작업을 반복합니다.
단계 2: MCP 서버 엔드포인트 생성
프로젝트 내에서 MCP 서버 탭을 열고 MCP 서버 추가를 클릭합니다. 서버에 설명적인 이름을 지정합니다 — 예를 들어, "지식 근로자 맥락" — 그런 다음 생성을 클릭합니다. MemoryLake는 세 가지 값을 반환합니다: 키 ID, 비밀 및 엔드포인트 URL. 비밀을 즉시 복사합니다; 한 번만 표시되며 나중에 검색할 수 없습니다.
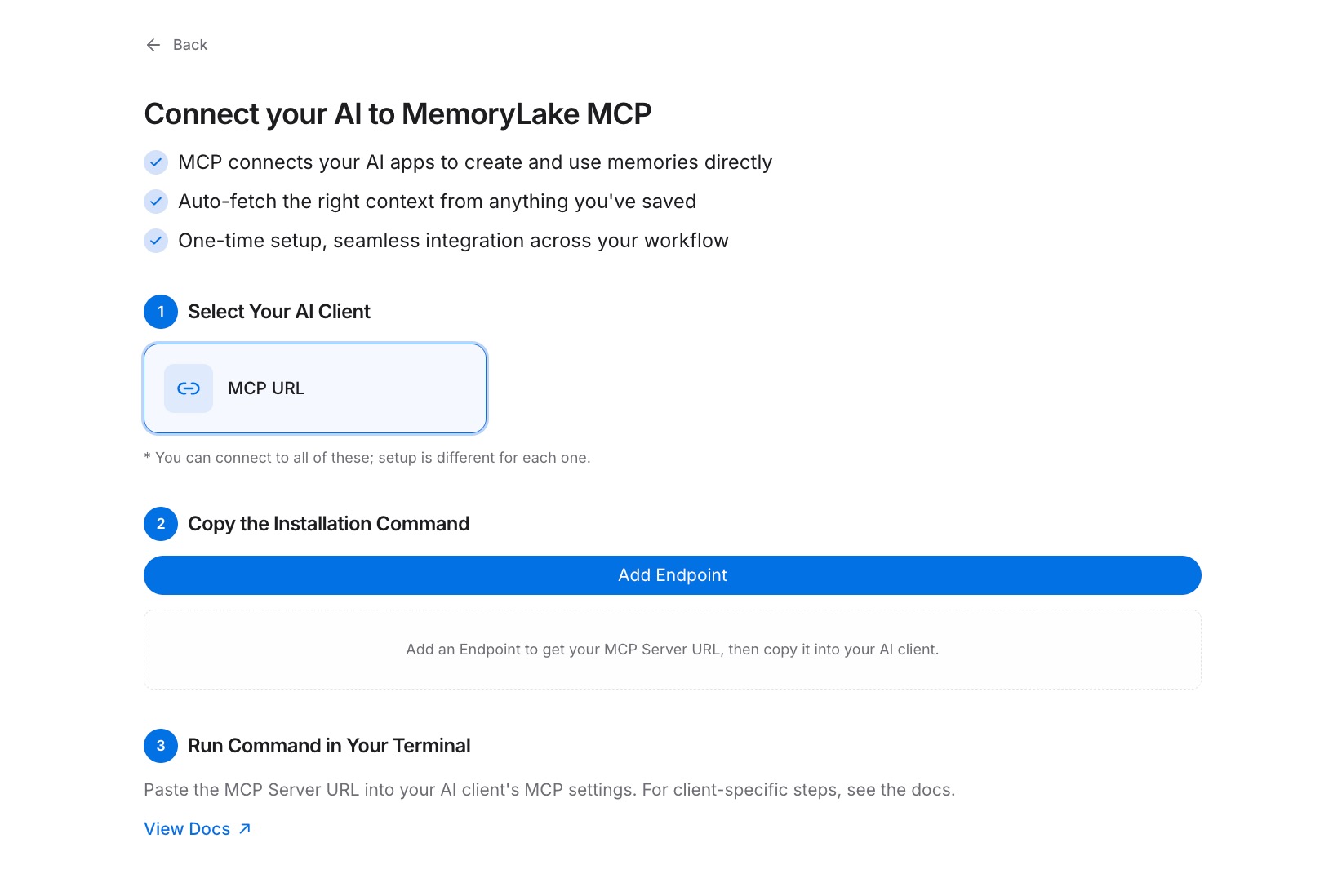
단계 3: MCP를 통해 AI 도구 연결
연결할 첫 번째 AI 도구에서 MCP 구성을 엽니다. 엔드포인트 URL을 새 MCP 서버로 등록하고 비밀을 인증을 위한 Bearer 토큰으로 설정합니다. 구성을 저장하고 도구를 재시작합니다. 이 시점부터 도구는 필요에 따라 프로젝트를 읽을 수 있습니다. 사용하는 모든 다른 AI 도구에 대해 이 단계를 반복합니다 — 각 도구는 동일한 엔드포인트 URL에 연결되므로 모두 동일한 프로젝트에서 동일한 맥락을 읽습니다. 전체 구성 참조는 MCP 설정 가이드를 참조하십시오. [MemoryLake 무료 사용해보기]
도구별 내장 기억 vs MemoryLake
| 차원 | 도구별 내장 기억 | MemoryLake |
|---|---|---|
| 세션 간 지속성 | 다양함 (종종 요약됨) | 예 — 문자 그대로 및 온전함 |
| 다른 AI 도구와의 작동 | 아니오 — 도구별 고립 | 예 — 하나의 프로젝트, 모든 도구 |
| 용량 | 제한되거나 요약됨 | 프로젝트에 따라 확장됨 |
| 버전 관리 | 아니오 | 예 (Git 스타일 기록) |
| 데이터 소유권 | 플랫폼 보유 | 당신이 소유함 (AES-256, 내보내기 또는 삭제) |
| 벤치마크 | — | LoCoMo #1 — 94.03% |
팁 및 모범 사례
- 각 기억 항목에 설명적인 이름을 지정합니다 (예: "작성 스타일: 짧은 문단, 능동태") 그러면 개별 AI 도구가 프로젝트의 모든 내용을 읽지 않고도 올바른 규칙을 검색할 수 있습니다.
- 작업 맥락에 따라 프로젝트를 분리합니다 — 클라이언트 참여를 위한 하나, 내부 연구를 위한 하나 — 그러면 AI는 현재 작업에 관련된 배경만 가져옵니다.
- 브리프 및 용어집과 같은 참조 파일은 기억으로 붙여넣기보다는 문서 드라이브에 저장합니다; 더 큰 구조화된 콘텐츠는 문서로서 더 잘 검색됩니다.
- MCP 키를 정기적으로 회전시키거나 키가 우연히 공유된 경우 즉시 회전시킵니다 — MCP 서버 탭에서 이전 키를 취소하고 대체 키를 생성합니다.
문제 해결
- AI 도구가 MemoryLake의 기억을 표시하지 않음: 엔드포인트 URL이 생성된 대로 정확히 입력되었는지 확인하고 도구의 MCP 구성이 저장되었으며 도구가 재시작되었는지 확인합니다.
- 모든 쿼리에서 인증 오류: 비밀이 일반 API 키나 사용자 이름/비밀번호 필드가 아닌 Bearer 토큰으로 붙여넣어졌는지 확인합니다.
- "비밀을 찾을 수 없음" 메시지: 비밀은 생성 시 한 번만 표시됩니다. 현재 키를 MCP 서버 탭에서 취소하고 새 키를 생성한 다음, 도구의 구성에서 Bearer 토큰을 업데이트합니다.
크로스 툴 기억 레이어를 한 번 구축하고 모든 곳에서 사용하세요
하나의 MemoryLake 프로젝트에 맥락을 로드하면 작업하는 모든 AI 도구가 동일한 출처를 읽습니다 — 도구를 전환할 때마다 당신이 누구인지 다시 설명할 필요가 없습니다.