간단한 답변
MemoryLake 프로젝트를 생성하고, 사실과 파일로 로드한 후, MCP 서버 엔드포인트를 생성합니다. 그런 다음 엔드포인트 URL과 비밀을 각 AI 도구의 MCP 구성에 Bearer 토큰으로 붙여넣습니다. 하나의 기억 저장소, 모든 AI, 세션 간 지속적입니다.
각 AI의 내장 기억이 크로스 모델 작업에 부족한 이유
대부분의 AI 도구는 어떤 형태의 기억을 가지고 있지만, 각 도구는 고립되어 있습니다. ChatGPT의 기억은 ChatGPT에만 존재합니다. Claude의 프로젝트 노트는 Gemini에서 보이지 않습니다. Cursor의 규칙은 Cursor 내부에만 존재합니다. 작업 흐름이 두 개 이상의 도구에 걸쳐 있을 때 — 하나에서 초안을 작성하고, 다른 곳에서 검토하고, 세 번째에서 코드를 실행할 때 — 서로가 알고 있는 내용을 공유하지 않습니다.
이 격차는 빠르게 확대됩니다. Claude에서 ChatGPT로 전환하여 계산을 확인할 때, ChatGPT는 한 시간 전에 Claude에게 말한 제약 조건을 알지 못합니다. Gemini를 열어 두 번째 의견을 요청할 때, 몇 주 전에 설정한 프로젝트 명명 규칙에 대해 전혀 알지 못합니다. 모든 핸드오프는 시간을 소모하며, 도구가 오래된 컨텍스트를 기반으로 작동할 위험이 있습니다.
부족한 것은 어떤 단일 AI의 바깥에 위치한 기억 레이어입니다 — 어떤 도구든 쿼리할 수 있고, 데이터 제어를 할 수 있는 레이어입니다. 이것이 MCP의 리소스 접근 패턴이 설계된 아키텍처적 격차이며, 이 가이드에서 다루는 내용입니다.
시작하기 전에
다음이 필요합니다:
- 무료 MemoryLake 계정
- 컨텍스트를 공유하고 싶은 최소 두 개의 AI 도구 (예: ChatGPT 및 Claude Code 또는 MCP 호환 에이전트)
- 지속하고 싶은 컨텍스트 — 사실, 규칙, 참조 문서 (PDF, Word, Excel, PowerPoint, 텍스트/Markdown 또는 이미지)
MCP로 크로스-AI 기억 설정하기 (단계별)
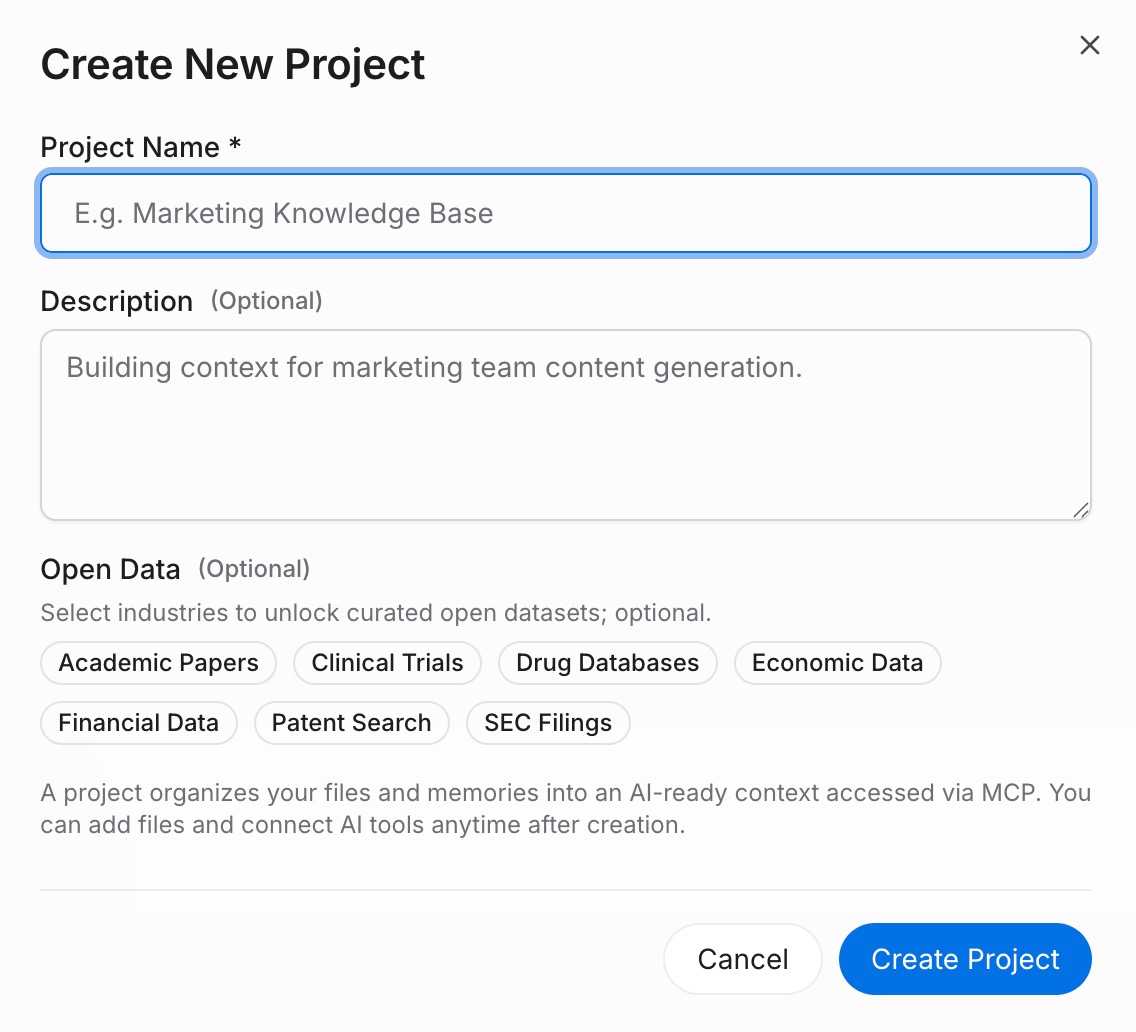
1단계: 기억 프로젝트 구축하기
MemoryLake에 로그인하고 프로젝트 관리를 엽니다. 프로젝트 생성을 클릭하고 설명적인 이름을 지정합니다 — 예를 들어, "공유 AI 컨텍스트" 또는 프로젝트 이름. 문서 드라이브를 열고 업로드를 클릭하여 참조 파일을 추가합니다. 문서 탭 → 문서 추가 → 확인으로 프로젝트에 첨부합니다. 그런 다음 기억 탭 → 기억 추가를 열어 AI가 항상 알아야 할 규칙, 선호도 또는 사실을 캡처합니다 → 저장.
2단계: MCP 서버 엔드포인트 생성하기
MCP 서버 탭 → MCP 서버 추가로 이동합니다. 서버에 범위를 반영하는 레이블을 지정합니다 — 예를 들어, "크로스-AI 기억 엔드포인트" — 그런 다음 생성을 클릭합니다. MemoryLake는 Key ID, Secret, Endpoint URL의 세 가지 값을 반환합니다. Secret을 지금 복사하세요; 한 번만 표시됩니다. 대화 상자를 닫기 전에 비밀번호 관리자나 비밀 금고에 저장하세요.
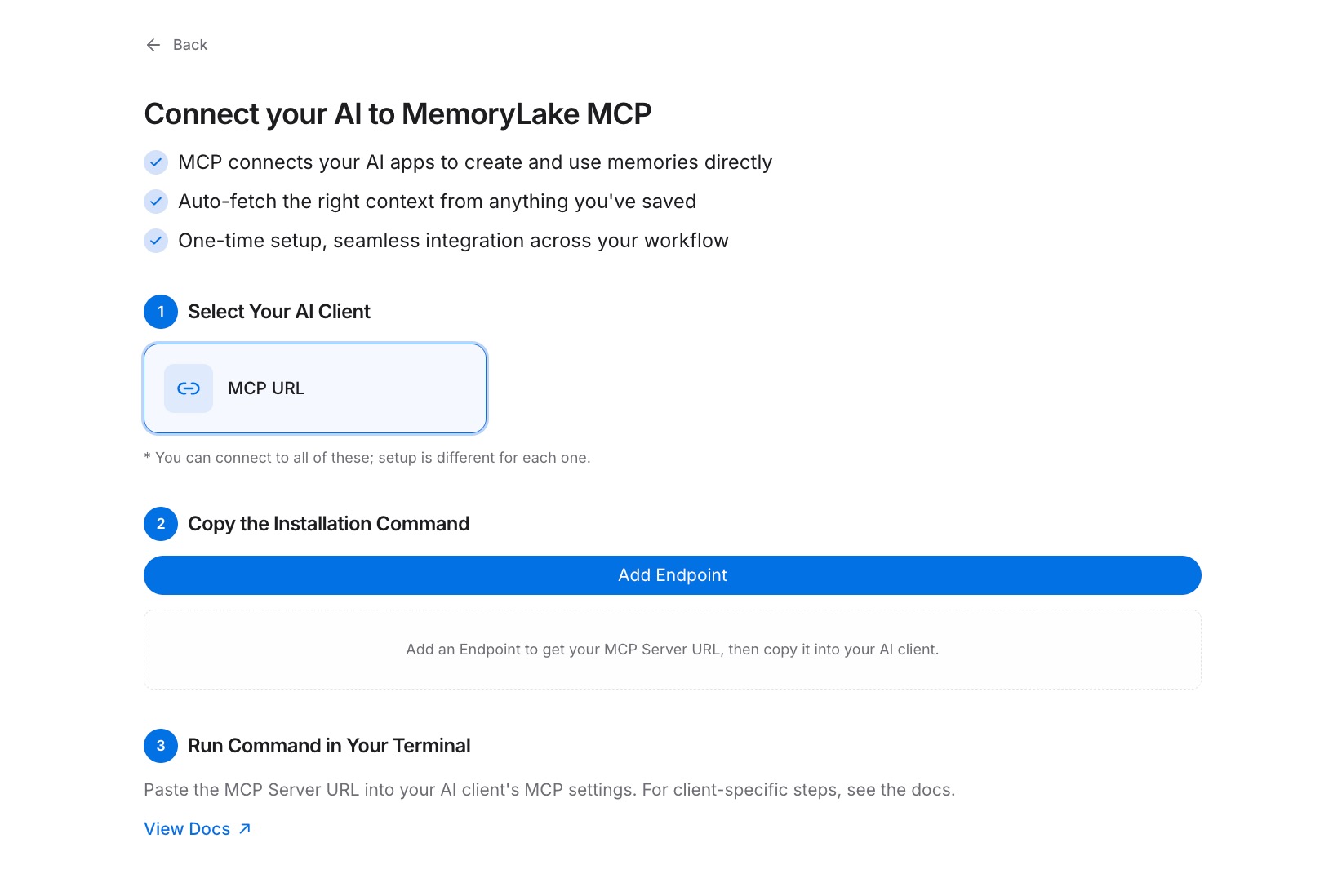
3단계: 각 AI 도구를 MCP로 연결하기
연결하려는 각 AI 도구의 MCP 구성을 엽니다. Endpoint URL을 서버 URL 필드에 붙여넣고 Secret을 인증 헤더의 Bearer 토큰으로 입력합니다. 작업 흐름의 모든 도구에 대해 반복합니다 — 이제 각 도구는 동일한 MemoryLake 프로젝트에서 읽고 쓸 수 있습니다. 정확한 구성 구문은 MCP 설정 가이드를 참조하세요. Claude Code를 사용하는 경우, Claude Code 통합 페이지에 전용 설정 단계가 있습니다. [MemoryLake 무료 체험하기]
AI 내장 기억 vs MemoryLake
| 차원 | 도구별 내장 기억 | MemoryLake |
|---|---|---|
| 세션 간 지속 | 때때로 (도구에 따라 다름) | 예, 항상 |
| 다른 AI 간 작동 | 아니요 — 도구별 고립 | 예 — 모든 MCP 연결 도구 |
| 용량 | 제한적 (도구 정의) | 프로젝트에 따라 확장 |
| 버전 관리 | 아니요 | 예 (Git 스타일의 역사) |
| 데이터 소유권 | 도구 공급자가 제어 | 당신이 소유 (AES-256, 내보내기/삭제) |
| 벤치마크 | — | LoCoMo #1 — 94.03% |
팁 & 모범 사례
- 도구가 아닌 컨텍스트 도메인으로 조직하세요. 프로젝트의 이름을 주제나 클라이언트에 따라 지정하고, 콘텐츠를 처음 생성한 AI에 따라 지정하지 마세요 — 모든 도구가 모든 프로젝트를 사용할 수 있어야 합니다.
- 기억 항목에 상시 규칙을 보관하고 문서 드라이브에 참조 자료를 보관하세요. 짧은 기억 항목은 각 쿼리에서 빠르게 검색됩니다; 큰 문서는 문서 드라이브에 보관하여 효율적으로 색인화되고 청크화됩니다.
- 일정에 따라 Secret을 회전하세요. MCP 서버 탭에서 새 키를 생성하고 각 도구의 구성을 업데이트하면, 이전 자격 증명은 저장된 컨텍스트에 방해 없이 작동을 중단합니다.
- 파일을 업데이트할 때 문서 버전 노트를 추가하세요. MemoryLake는 Git 스타일의 역사를 추적하므로, 문서를 교체할 때 간단한 노트를 추가하면 AI가 어떤 버전을 사용했는지 감사하기 쉽습니다.
문제 해결
- 한 AI는 오래된 컨텍스트를 보고 다른 AI는 업데이트를 봅니다: 모든 도구가 동일한 Endpoint URL 및 프로젝트 ID를 가리키는지 확인하세요. URL 불일치는 서로 다른 프로젝트를 읽고 있다는 의미입니다.
- Secret을 회전한 후 인증이 거부됨: 이전 Bearer 토큰은 회전 시 취소됩니다. MCP 서버 탭에서 생성된 새 Secret으로 모든 도구의 MCP 구성을 업데이트하세요.
- 첫 연결 시 "Secret을 찾을 수 없음" 오류: Secret은 생성 시 한 번만 표시됩니다. 기존 키를 취소하고 MCP 서버 탭에서 다시 생성하여 새 자격 증명을 발급받으세요.
하나의 기억 레이어, 모든 AI
도구를 전환할 때마다 자신을 다시 소개하는 것을 중단하세요. 한 번 연결하면, 작업 흐름의 모든 AI가 동일한 지속적인 컨텍스트를 공유합니다.