La respuesta corta
Los trabajadores del conocimiento pueden configurar la memoria de IA entre herramientas creando un Proyecto en MemoryLake, cargando su contexto en él (documentos, reglas, preferencias), generando un endpoint de Servidor MCP y conectando cada herramienta de IA a ese endpoint. Cada herramienta lee el mismo Proyecto — no hay necesidad de re-explicar el contexto cuando cambias de herramienta.
Por qué la memoria incorporada de cada herramienta de IA es insuficiente
La mayoría de las herramientas de IA ofrecen alguna forma de historial de sesión o una función de memoria ligera, pero cada una es un silo. El contexto que has construido dentro de ChatGPT no viaja a Claude. Las reglas que estableces en tu agente de codificación no aparecen en tu herramienta de investigación. Terminas manteniendo múltiples copias inconsistentes de "quién eres y qué necesitas" — y inevitablemente se desincronizan.
Tampoco hay propiedad compartida. Cada herramienta resume o interpreta tu contexto a su manera, lo que significa que la instrucción precisa que escribiste se parafrasea, recorta o descarta. Cuando cambias de herramienta a mitad de proyecto, sientes el costo de inmediato: cinco minutos explicando tus limitaciones, otros dos aclarando tu terminología, y luego la inevitable corrección cuando la IA asume algo incorrecto.
Para un trabajador del conocimiento que equilibra investigación, redacción, análisis de datos y comunicación a través de tres o cuatro herramientas de IA en una sola tarde, esa fricción se acumula rápidamente. La verdadera brecha no es la memoria de ninguna herramienta en particular — es que no existe una única fuente de verdad para tu contexto en su totalidad.
Antes de empezar
Necesitarás:
- Una cuenta gratuita de MemoryLake
- Al menos una herramienta de IA que soporte MCP (Claude Desktop, Cursor, o cualquier otro cliente compatible con MCP)
- El contexto que repites con más frecuencia — resúmenes de proyectos, reglas de estilo, preferencias o archivos de referencia (PDF, Word, Excel, PowerPoint, Markdown o imágenes)
Cómo configurar la memoria entre herramientas para trabajadores del conocimiento (paso a paso)
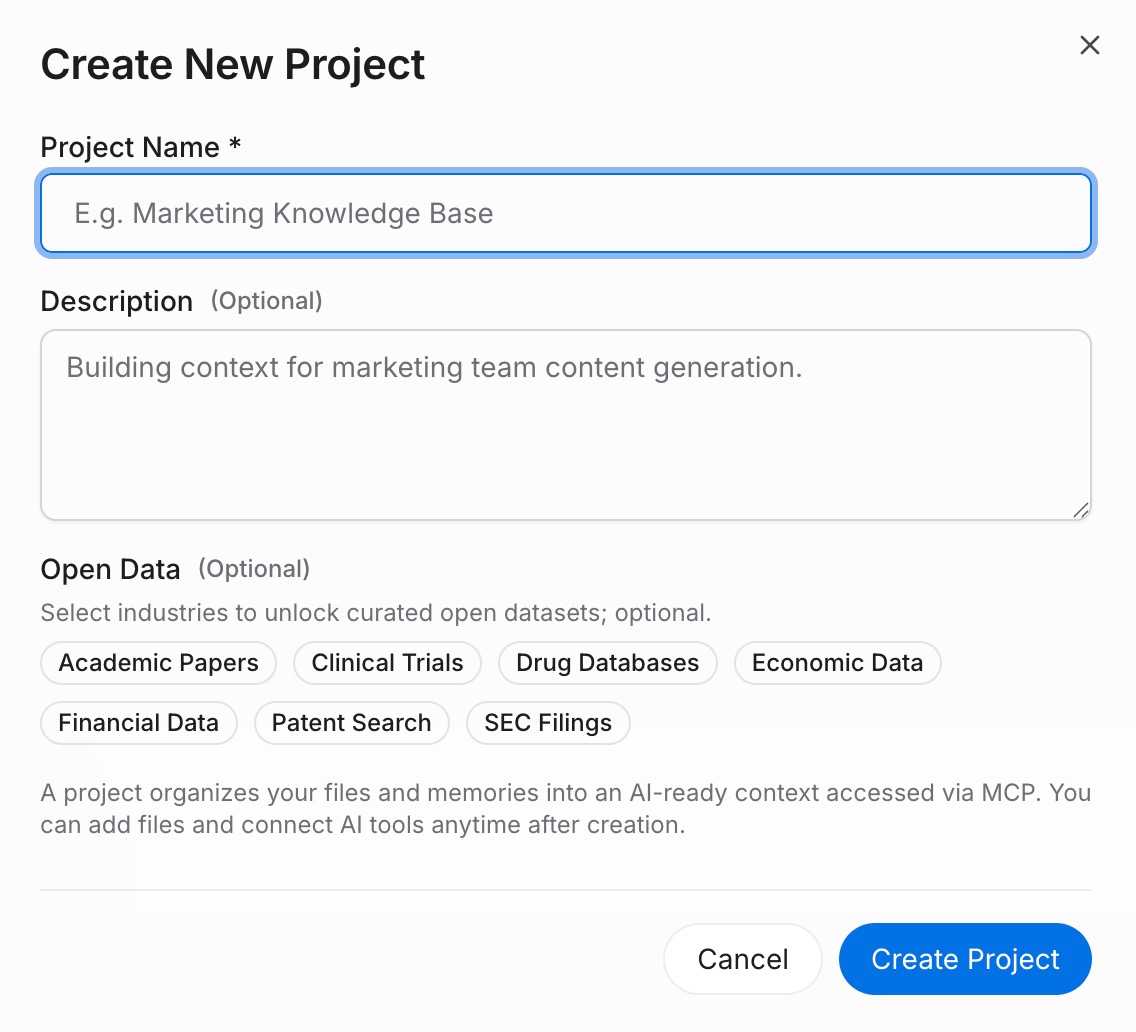
Paso 1: Construir un Proyecto de memoria
Inicia sesión en MemoryLake y ve a Gestión de Proyectos. Haz clic en Crear Proyecto y dale un nombre claro — por ejemplo, "Contexto de Trabajo 2026." Dentro del proyecto, abre el Document Drive y haz clic en Subir para agregar archivos de referencia como un resumen de proyecto, guía de estilo o notas de investigación. Luego abre la Pestaña de Documentos, haz clic en Agregar Documentos, y haz clic en Confirmar para adjuntar los archivos subidos al proyecto. A continuación, abre la Pestaña de Recuerdos, haz clic en Agregar Recuerdo, escribe una regla o preferencia permanente (por ejemplo, tu formato de respuesta preferido, una limitación recurrente o terminología clave), y haz clic en Guardar. Repite para cada regla que sueles repetir al incorporar una herramienta de IA.
Paso 2: Generar un endpoint de Servidor MCP
Dentro del proyecto, abre la Pestaña de Servidores MCP y haz clic en Agregar Servidor MCP. Dale al servidor un nombre descriptivo — por ejemplo, "Contexto del Trabajador del Conocimiento" — luego haz clic en Generar. MemoryLake devuelve tres valores: un ID de Clave, un Secreto, y una URL de Endpoint. Copia el Secreto inmediatamente; se muestra solo una vez y no se puede recuperar más tarde.
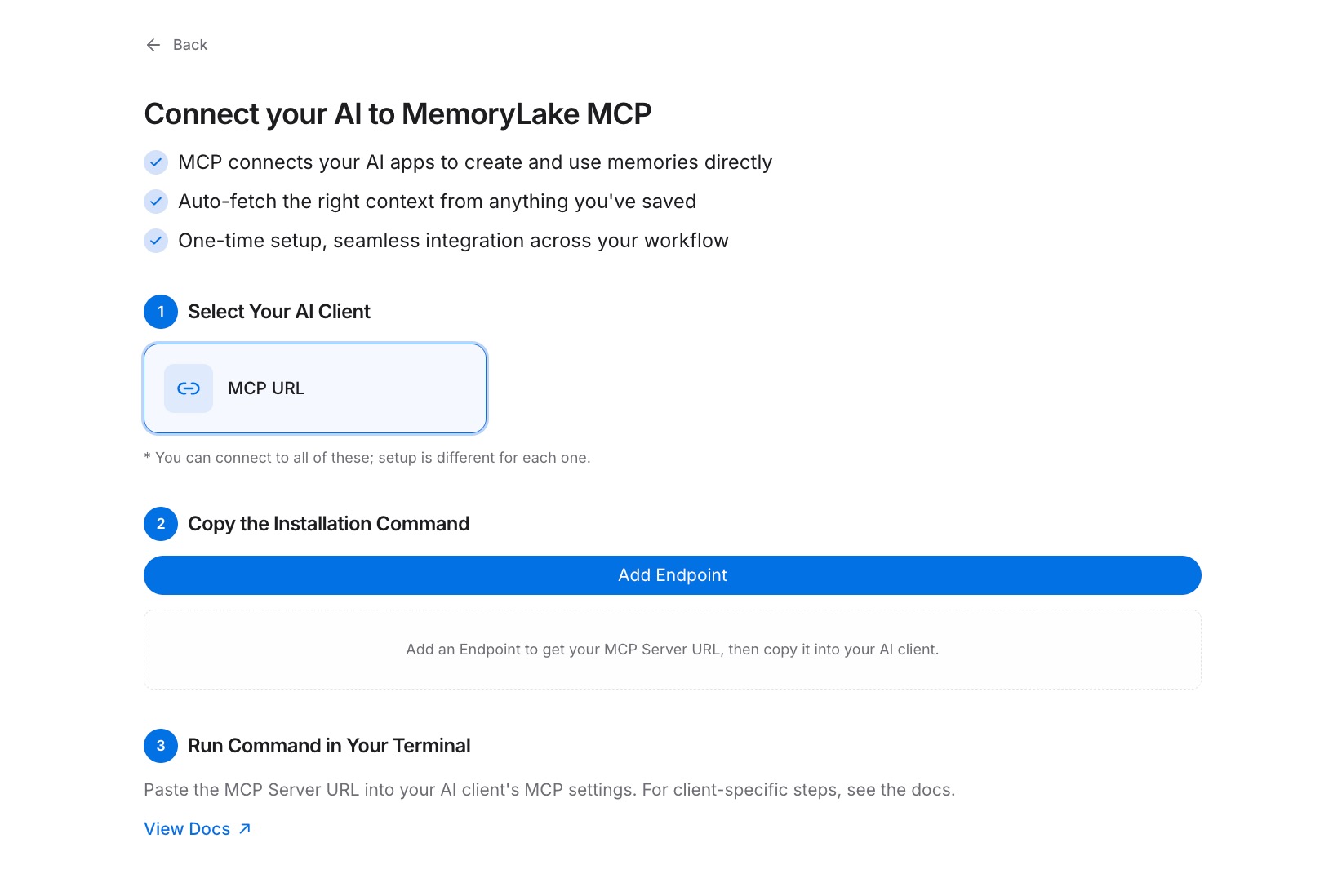
Paso 3: Conectar tu herramienta de IA a través de MCP
Abre la configuración de MCP en la herramienta de IA que quieras conectar primero. Registra la URL de Endpoint como un nuevo servidor MCP y establece el Secreto como un token Bearer para autenticación. Guarda la configuración y reinicia la herramienta. A partir de este momento, la herramienta puede leer tu Proyecto bajo demanda. Repite este paso para cada otra herramienta de IA que uses — cada una se conecta a la misma URL de Endpoint, por lo que todas leen el mismo contexto del mismo Proyecto. Consulta la guía de configuración de MCP para la referencia completa de configuración. [Prueba MemoryLake gratis]
Memoria incorporada por herramienta vs MemoryLake
| Dimensión | Memoria incorporada por herramienta | MemoryLake |
|---|---|---|
| Persiste entre sesiones | Varía (a menudo resumida) | Sí — palabra por palabra e intacta |
| Funciona entre otras herramientas de IA | No — silo por herramienta | Sí — un Proyecto, todas las herramientas |
| Capacidad | Limitada o resumida | Escala con tu Proyecto |
| Control de versiones | No | Sí (historial estilo Git) |
| Propiedad de datos | Sostenida por la plataforma | Tú la posees (AES-256, exportar o eliminar) |
| Referencia | — | LoCoMo #1 — 94.03% |
Consejos y mejores prácticas
- Nombra cada entrada de Memoria de manera descriptiva (por ejemplo, "Estilo de escritura: párrafos cortos, voz activa") para que las herramientas de IA individuales puedan recuperar la regla correcta sin leer todo en el Proyecto.
- Separa los Proyectos por contexto de trabajo — uno para un compromiso con un cliente, uno para investigación interna — para que la IA solo extraiga el contexto relevante para la tarea en cuestión.
- Almacena archivos de referencia como resúmenes y glosarios en el Document Drive en lugar de pegarlos como recuerdos; el contenido estructurado más grande se recupera mejor como documentos.
- Rota tus claves MCP en un horario regular o inmediatamente si una clave se comparte accidentalmente — revoca la antigua en la Pestaña de Servidores MCP y genera una nueva.
Solución de problemas
- La herramienta de IA no muestra memoria de MemoryLake: confirma que la URL de Endpoint esté ingresada exactamente como se generó y que la configuración de MCP de la herramienta se haya guardado y la herramienta se haya reiniciado.
- Errores de autenticación en cada consulta: verifica que el Secreto esté pegado como un token Bearer, no como una clave API simple o campo de nombre de usuario/contraseña.
- Mensaje de "Secreto no encontrado": el Secreto se muestra solo una vez en el momento de la generación. Revoca la clave actual en la Pestaña de Servidores MCP y genera una nueva, luego actualiza el token Bearer en la configuración de tu herramienta.
Construye tu capa de memoria entre herramientas una vez, úsala en todas partes
Carga tu contexto en un solo Proyecto de MemoryLake y cada herramienta de IA con la que trabajes lee la misma fuente — no más re-explicar quién eres cada vez que cambias de herramienta.